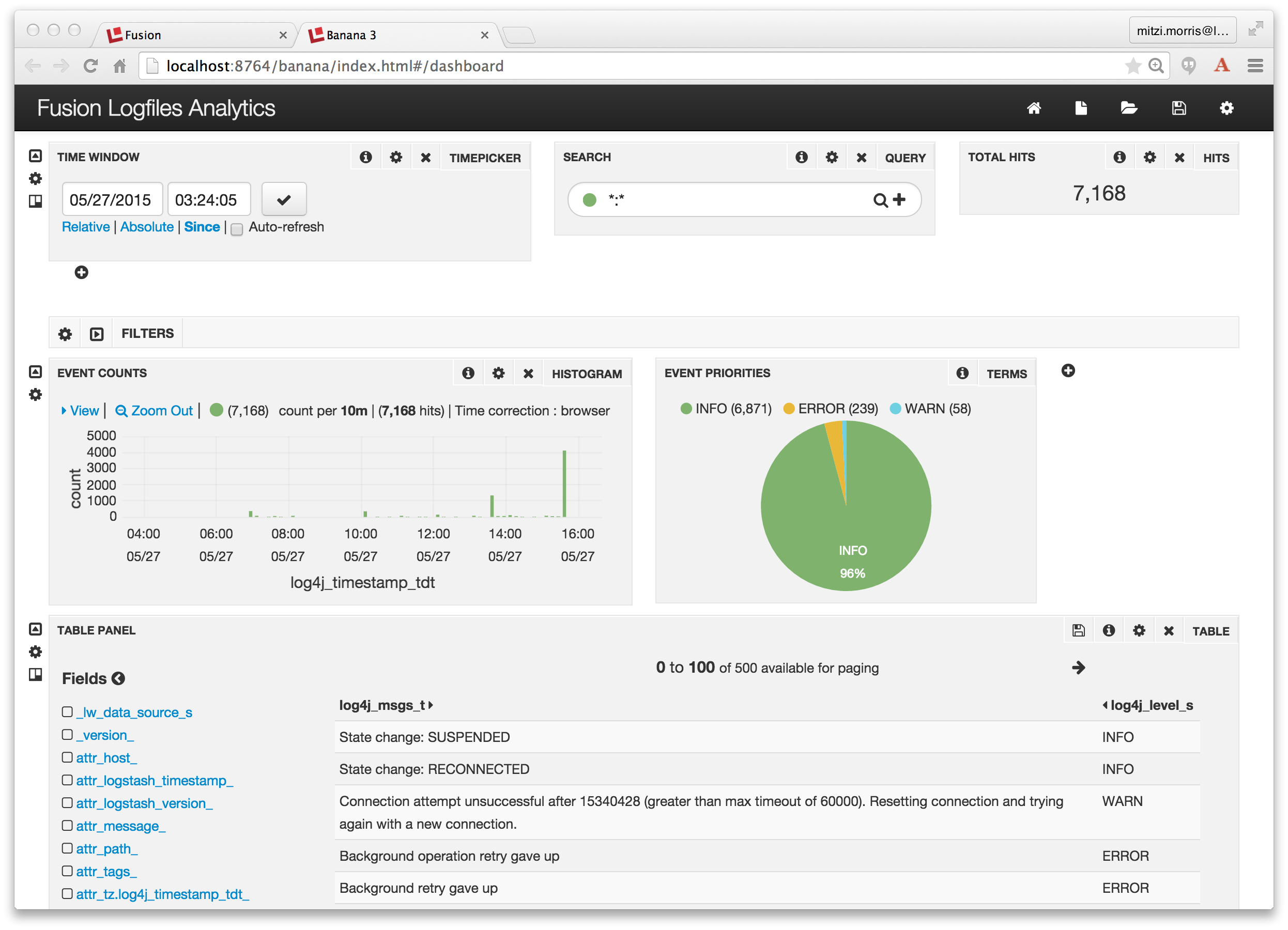
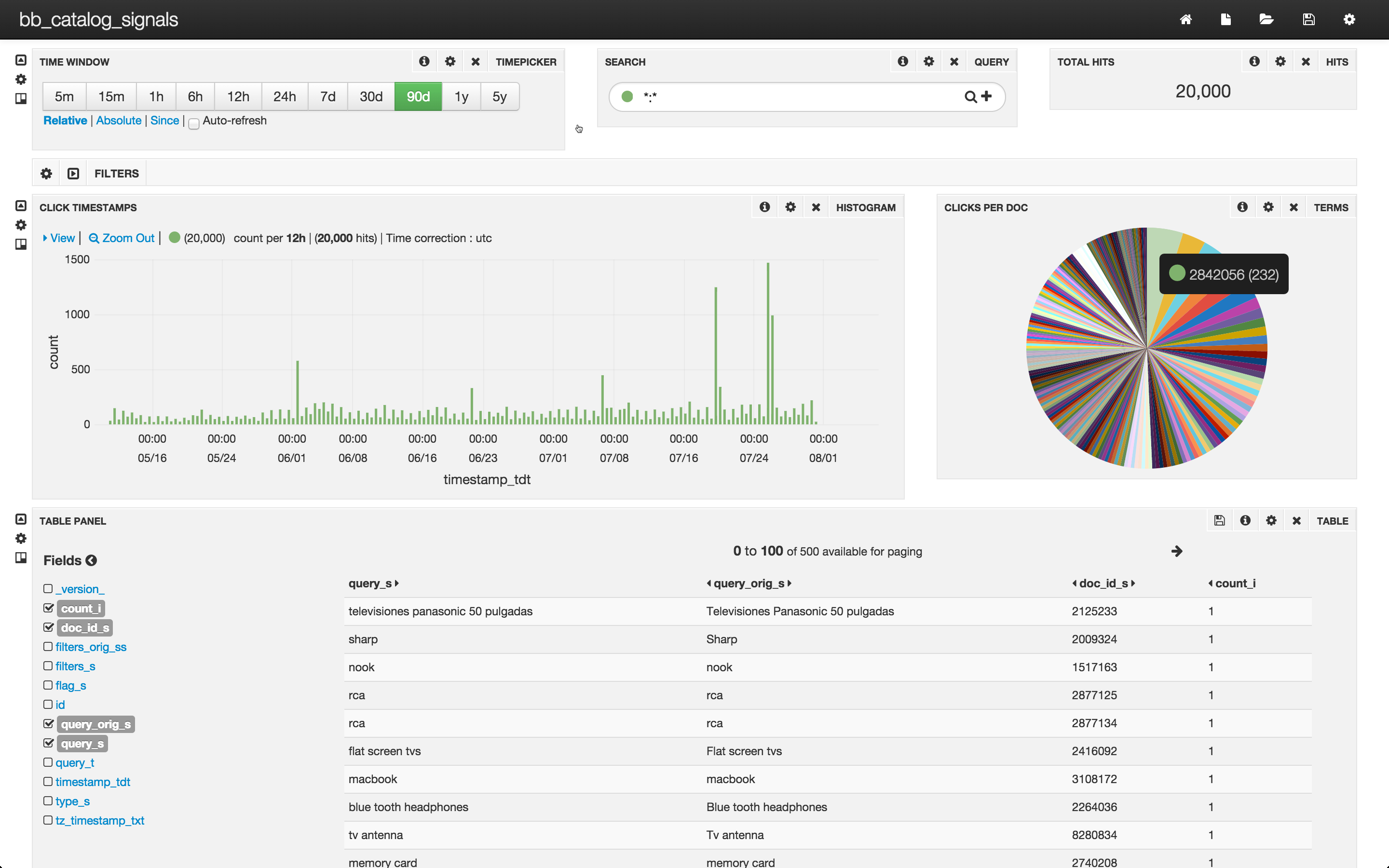
Series Introduction
This is the first in a three part series demonstrating the ease and succinctness possible with Solr out of the box. The three parts to this are:
- Getting data into Solr using bin/post
- Visualizing search results: /browse and beyond
- Putting it together realistically: example/files – a concrete useful domain-specific example of bin/post and /browse
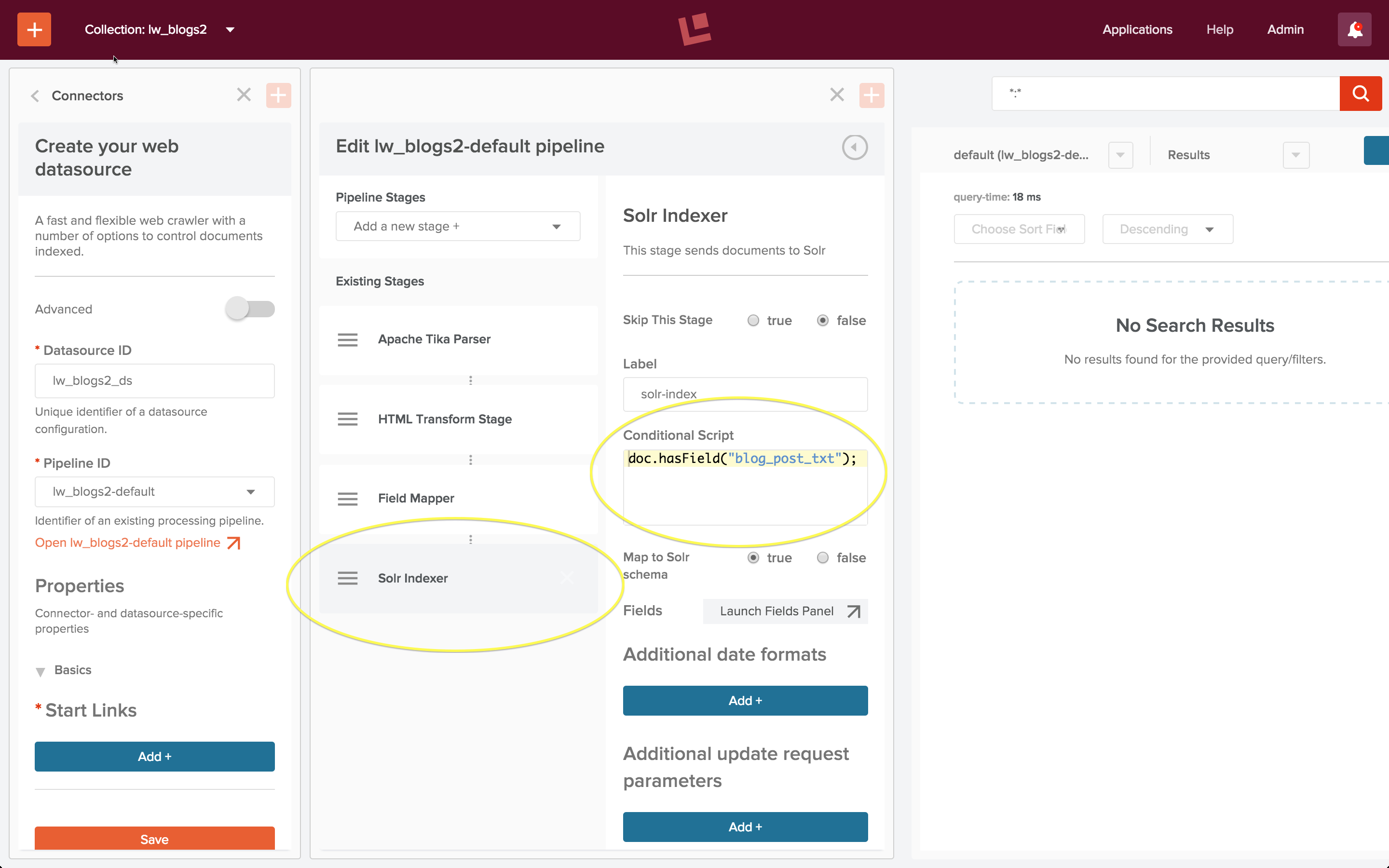
Introducing bin/post: a built-in Solr 5 data indexing tool
In the beginning was the command-line…
As part of the ease of use improvements in Solr 5, the
bin/post tool was created to allow you to more easily index data and documents. This article illustrates and explains how to use this tool.
For those (pre-5.0) Solr veterans who have most likely run Solr’s “example”, you’ll be familiar with post.jar, under example/exampledocs. You may have only used it when firing up Solr for the first time, indexing example tech products or book data. Even if you haven’t been using post.jar, give this new interface a try if even for the occasional sending of administrative commands to your Solr instances. See below for some interesting simple tricks that can be done using this tool.
Let’s get started by firing up Solr and creating a collection:
$ bin/solr start
$ bin/solr create -c solr_docs
The
bin/post tool can index a directory tree of files, and the Solr distribution has a handy
docs/ directory to demonstrate this capability:
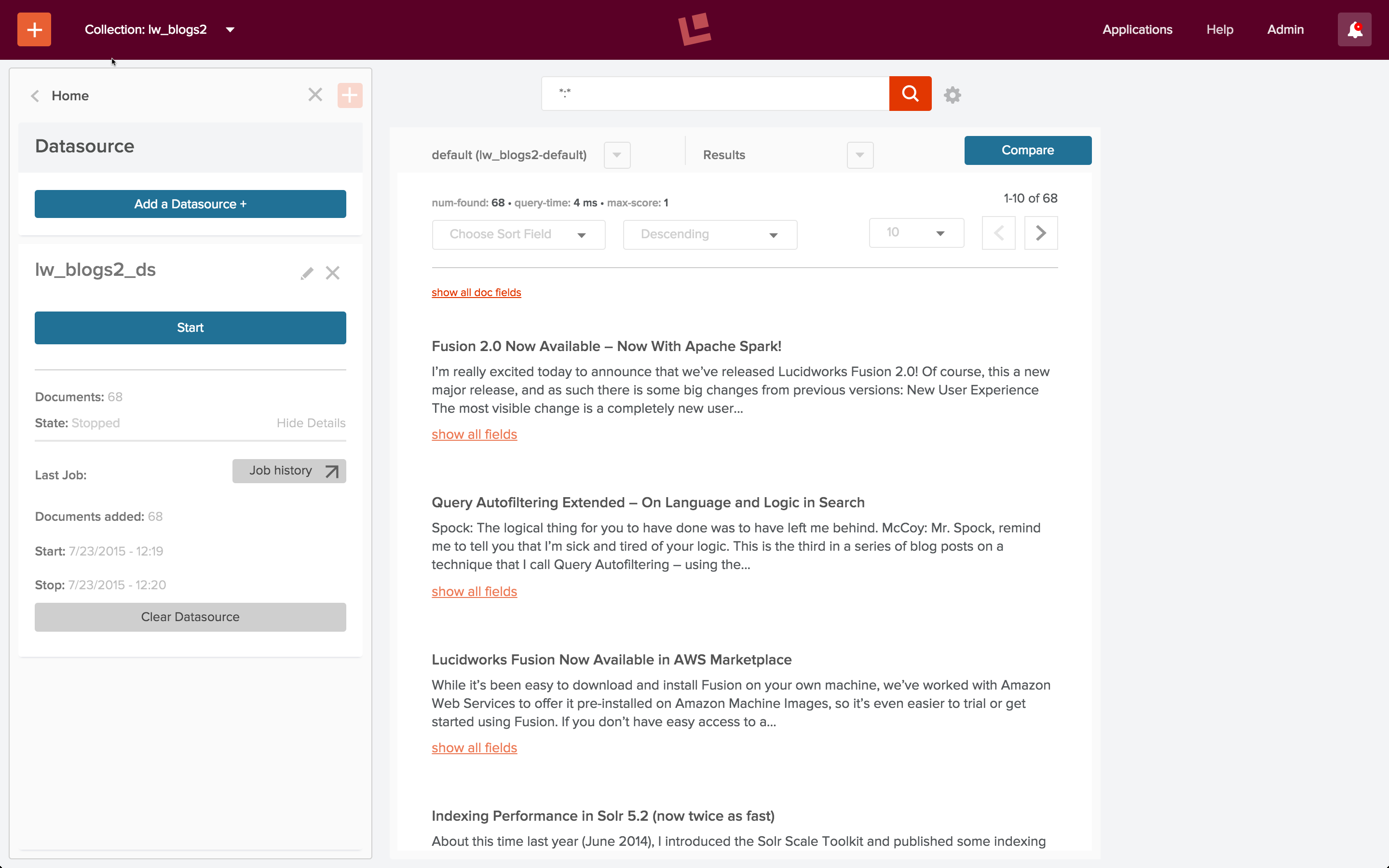
$ bin/post -c solr_docs docs/
java -classpath /Users/erikhatcher/solr-5.3.0/dist/solr-core-5.3.0.jar -Dauto=yes -Dc=solr_docs -Ddata=files -Drecursive=yes org.apache.solr.util.SimplePostTool /Users/erikhatcher/solr-5.3.0/docs/
SimplePostTool version 5.0.0
Posting files to [base] url http://localhost:8983/solr/solr_docs/update...
Entering auto mode. File endings considered are xml,json,csv,pdf,doc,docx,ppt,pptx,xls,xlsx,odt,odp,ods,ott,otp,ots,rtf,htm,html,txt,log
Entering recursive mode, max depth=999, delay=0s
Indexing directory /Users/erikhatcher/solr-5.3.0/docs (3 files, depth=0)
.
.
.
3575 files indexed.
COMMITting Solr index changes to http://localhost:8983/solr/solr_docs/update...
Time spent: 0:00:30.705
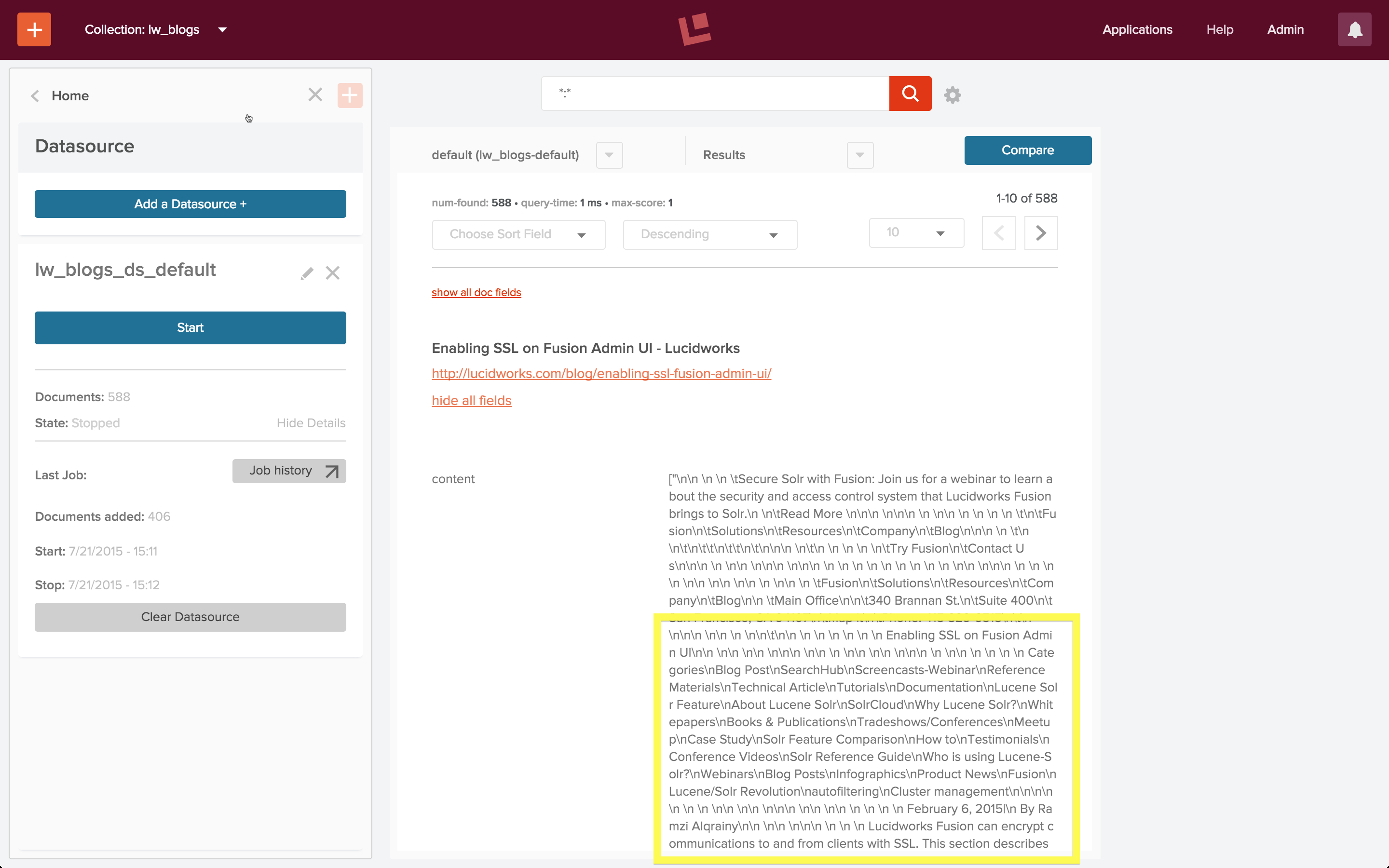
30 seconds later we have Solr’s
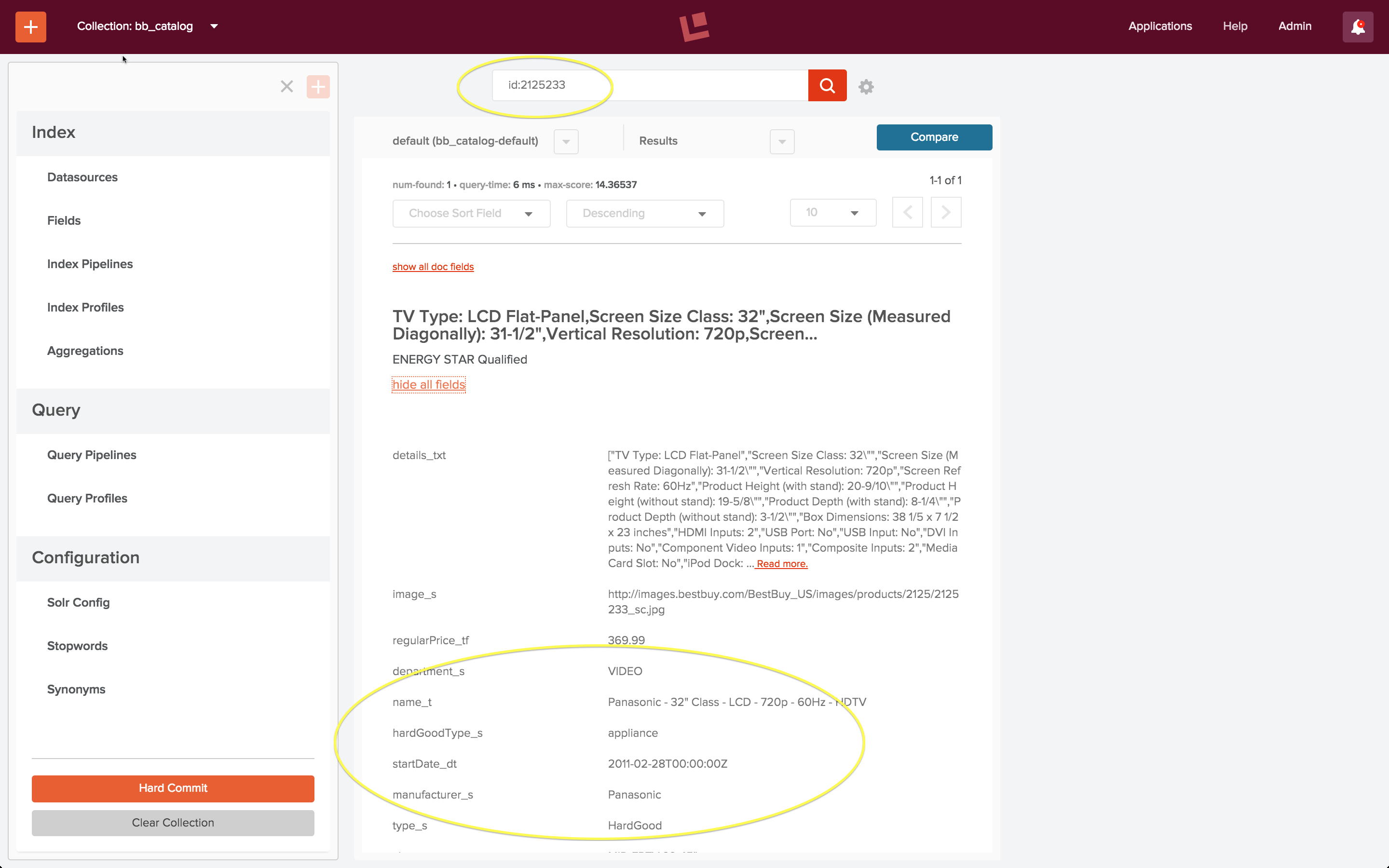
docs/ directory indexed and available for searching. Foreshadowing to the next post in this series, check out http://localhost:8983/solr/solr_docs/browse?q=faceting to see what you’ve got.
Is there anything bin/post can do that clever
curling can’t do? Not a thing, though you’d have to iterate over a directory tree of files or do web crawling and parsing out links to follow for entirely comparable capabilities. bin/post is meant to simplify the (command-line) interface for many common Solr ingestion and command needs.
Usage
The tool provides solid
-h help, with the abbreviated usage specification being:
$ bin/post -h
Usage: post -c <collection> [OPTIONS] <files|directories|urls|-d ["...",...]>
or post -help
collection name defaults to DEFAULT_SOLR_COLLECTION if not specified
...
See the full
bin/post -h output for more details on parameters and example usages. A collection, or URL, must always be specified with
-c (or by
DEFAULT_SOLR_COLLECTION set in the environment) or
-url. There are parameters to control the base Solr URL using
-host,
-port, or the full
-url. Note that when using
-url it must be the full URL, including the core name all the way through to the /update handler, such as
-url http://staging_server:8888/solr/core_name/update.
Indexing “rich documents” from the file system or web crawl
File system indexing was demonstrated above, indexing Solr’s docs/ directory which includes a lot of HTML files. Another fun example of this is to index your own documents folder like this:
bin/solr create -c my_docs
bin/post -c my_docs ~/Documents
There’s a constrained list of file types (by file extension) that
bin/post will pass on to Solr, skipping the others.
bin/post -h provides the default list used. To index a .png file, for example, set the
-filetypes parameter:
bin/post -c test -filetypes png image.png. To not skip any files, use “*” for the filetypes setting:
bin/post -c test -filetypes "*" docs/ (
note the double-quotes around the asterisk, otherwise your shell may expand that to a list of files and not operate as intended)
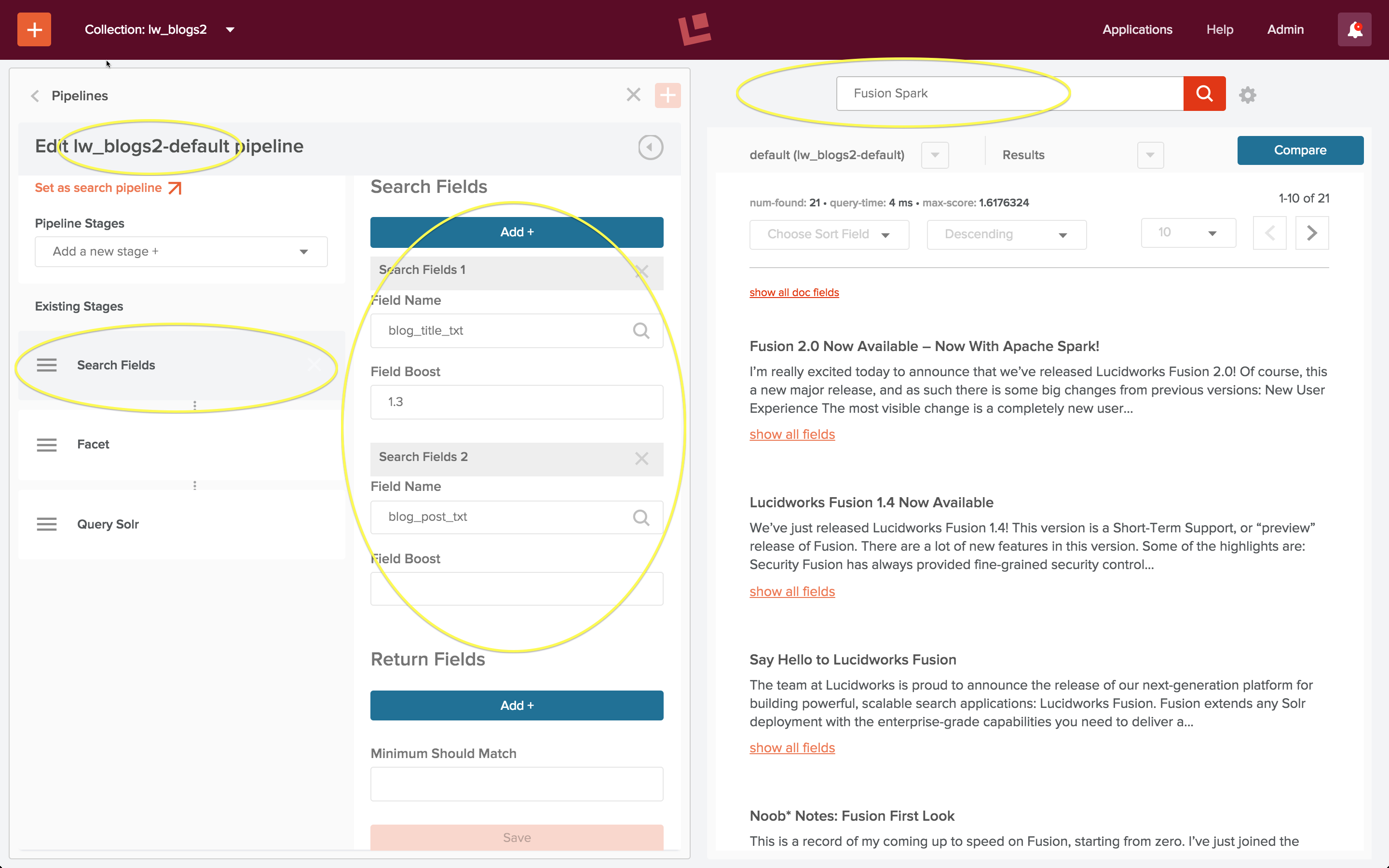
Browse and search your own documents at http://localhost:8983/solr/my_docs/browse
Rudimentary web crawl
Careful now: crawling web sites is no trivial task to do well. The web crawling available from
bin/post is very basic, single-threaded, and not intended for serious business. But it sure is fun to be able to fairly quickly index a basic web site and get a feel for the types of content processing and querying issues to face as a production scale crawler or other content acquisition means are in the works:
$ bin/solr create -c site
$ bin/post -c site http://lucidworks.com -recursive 2 -delay 1 # (this will take some minutes)
Web crawling adheres to the same content/file type filtering as the file crawling mentioned above; use
-filetypes as needed. Again, check out /browse; for this example try http://localhost:8983/solr/site/browse?q=revolution
Indexing CSV (column/delimited) files
Indexing CSV files couldn’t be easier! It’s just this, where data.csv is a standard CSV file:
$ bin/post -c collection_name data.csv
CSV files are handed off to the /update handler with the content type of “text/csv”. It detects it is a CSV file by the .csv file extension. Because the file extension is used to pick the content type and it currently only has a fixed “.csv” mapping to text/csv, you will need to explicitly set the content
-type like this if the file has a different extension:
$ bin/post -c collection_name -type text/csv data.file
If the delimited file does not have a first line of column names, some columns need excluding or name mapping, the file is tab rather than comma delimited, or you need to specify any of the
various options to the CSV handler, the
-params option can be used. For example, to index a tab-delimited file, set the
separator parameter like this:
$ bin/post -c collection_name data.tsv -type text/csv -params "separator=%09"
The key=value pairs specified in
-params must be URL encoded and ampersand separated (tab is url encoded as %09). If the first line of a CSV file is data rather than column names, or you need to override the column names, you can provide the
fieldnames parameter, setting header=true if the first line should be ignored:
$ bin/post -c collection_name data.csv -params "fieldnames=id,foo&header=true"
Here’s a neat trick you can do with CSV data, add a “data source”, or some type of field to identify which file or data set each document came from. Add a
literal.<field_name>= parameter like this:
$ bin/post -c collection_name data.csv -params "literal.data_source=temp"
Provided your schema allows for a data_source field to appear on documents, each file or set of files you load get tagged to some scheme of your choosing making it easy to filter, delete, and operate on that data subset. Another literal field name could be the filename itself, just be sure that the file being loaded matches the value of the field (easy to up-arrow and change one part of the command-line but not another that should be kept in sync).
Indexing JSON
If your data is in
Solr JSON format, it’s just
bin/post -c collection_name data.json.
Arbitrary, non-Solr, JSON can be mapped as well. Using the exam grade data and example from
here, the splitting and mapping parameters can be specified like this:
$ bin/post -c collection_name grades.json -params "split=/exams&f=first:/first&f=last:/last&f=grade:/grade&f=subject:/exams/subject&f=test:/exams/test&f=marks:/exams/marks&json.command=false"
Note that
json.command=false had to be specified so the JSON is interpreted as data not as potential Solr commands.
Indexing Solr XML
Good ol’ Solr XML, easy peasy:
bin/post -c collection_name data.xml.
Alas, there’s currently no splitting and mapping capabilities for arbitrary XML using
bin/post; use Data Import Handler with the
XPathEntityProcessor to accomplish this for now. See
SOLR-6559 for more information on this future enhancement.
Sending commands to Solr
Besides indexing documents,
bin/post can also be used to issue commands to Solr. Here are some examples:
- Commit:
bin/post -c collection_name -out yes -type application/json -d '{commit:{}}'
Note: For a simple commit, no data/command string is actually needed. An empty, trailing -d suffices to force a commit, like this – bin/post -c collection_name -d
- Delete a document by id:
bin/post -c collection_name -type application/json -out yes -d '{delete: {id: 1}}'
- Delete documents by query:
bin/post -c test -type application/json -out yes -d '{delete: {query: "data_source:temp"}}'
The
-out yes echoes the HTTP response body from the Solr request, which generally isn’t any more helpful with indexing errors, but is nice to see with commands like commit and delete, even on success.
Commands, or even documents, can be piped through
bin/post when
-d dangles at the end of the command-line:
# Pipe a commit command
$ echo '{commit: {}}' | bin/post -c collection_name -type application/json -out yes -d
# Pipe and index a CSV file
$ cat data.csv | bin/post -c collection_name -type text/csv -d
Inner workings of bin/post
The
bin/post tool is a straightforward Unix shell script that processes and validates command-line arguments and launches a Java program to do the work of posting the file(s) to the appropriate update handler end-point. Currently, SimplePostTool is the Java class used to do the work (the core of the infamous
post.jar of yore). Actually post.jar still exists and is used under
bin/post, but this is an implementation detail that
bin/post is meant to hide.
SimplePostTool (not the bin/post wrapper script) uses the file extensions to determine the Solr end-point to use for each POST. There are three special types of files that POST to Solr’s /update end-point: .json, .csv, and .xml. All other file extensions will get posted to the
URL+/extract end-point, richly parsing a wide variety of file types. If you’re indexing CSV, XML, or JSON data and the file extension doesn’t match or isn’t actually a file (if you’re using the
-d option) be sure to explicitly set the
-type to text/csv, application/xml, or application/json.
Stupid bin/post tricks
Introspect rich document parsing and extraction
Want to see how Solr’s rich document parsing sees your files? Not a new feature, but a neat one that can be exploited through
bin/post by sending a document to the extract handler in a debug mode returning an XHTML view of the document, metadata and all. Here’s an example, setting
-params with some extra settings explained below:
$ bin/post -c test -params "extractOnly=true&wt=ruby&indent=yes" -out yes docs/SYSTEM_REQUIREMENTS.html
java -classpath /Users/erikhatcher/solr-5.3.0/dist/solr-core-5.3.0.jar -Dauto=yes -Dparams=extractOnly=true&wt=ruby&indent=yes -Dout=yes -Dc=test -Ddata=files org.apache.solr.util.SimplePostTool /Users/erikhatcher/solr-5.3.0/docs/SYSTEM_REQUIREMENTS.html
SimplePostTool version 5.0.0
Posting files to [base] url http://localhost:8983/solr/test/update?extractOnly=true&wt=ruby&indent=yes...
Entering auto mode. File endings considered are xml,json,csv,pdf,doc,docx,ppt,pptx,xls,xlsx,odt,odp,ods,ott,otp,ots,rtf,htm,html,txt,log
POSTing file SYSTEM_REQUIREMENTS.html (text/html) to [base]/extract
{
'responseHeader'=>{
'status'=>0,
'QTime'=>3},
''=>'<?xml version="1.0" encoding="UTF-8"?>
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<meta
name="stream_size" content="1100"/>
<meta name="X-Parsed-By"
content="org.apache.tika.parser.DefaultParser"/>
<meta
name="X-Parsed-By"
content="org.apache.tika.parser.html.HtmlParser"/>
<meta
name="stream_content_type" content="text/html"/>
<meta name="dc:title"
content="System Requirements"/>
<meta
name="Content-Encoding" content="UTF-8"/>
<meta name="resourceName"
content="/Users/erikhatcher/solr-5.2.0/docs/SYSTEM_REQUIREMENTS.html"/>
<meta
name="Content-Type"
content="text/html; charset=UTF-8"/>
<title>System Requirements</title>
</head>
<body>
<h1>System Requirements</h1>
...
</body>
</html>
',
'null_metadata'=>[
'stream_size',['1100'],
'X-Parsed-By',['org.apache.tika.parser.DefaultParser',
'org.apache.tika.parser.html.HtmlParser'],
'stream_content_type',['text/html'],
'dc:title',['System Requirements'],
'Content-Encoding',['UTF-8'],
'resourceName',['/Users/erikhatcher/solr-5.3.0/docs/SYSTEM_REQUIREMENTS.html'],
'title',['System Requirements'],
'Content-Type',['text/html; charset=UTF-8']]}
1 files indexed.
COMMITting Solr index changes to http://localhost:8983/solr/test/update?extractOnly=true&wt=ruby&indent=yes...
Time spent: 0:00:00.027
Setting
extractOnly=true instructs the extract handler to return the structured parsed information rather than actually index the document. Setting wt=ruby (ah yes! go ahead, try it in json or xml :) and indent=yes allows the output (be sure to specify
-out yes!) to render readably in a console.
Prototyping, troubleshooting, tinkering, demonstrating
It’s really handy to be able to test and demonstrate a feature of Solr by
“doing the simplest possible thing that will work” and
bin/post makes this a real joy. Here are some examples –
Does it match?
This technique allows you to easily index data and quickly see how queries work against it. Create a “playground” index and post a single document with fields id, description, and value:
$ bin/solr create -c playground
$ bin/post -c playground -type text/csv -out yes -d $'id,description,value\n1,are we there yet?,0.42'
Unix Note: that dollar-sign before the single-quoted CSV string is crucial for the new-line escaping to pass through properly. Or one could post the same data but putting the field names into a separate parameter using bin/post -c playground -type text/csv -out yes -params "fieldnames=id,description,value" -d '1,are we there yet?,0.42' avoiding the need for a new-line and the associated issue.
Does it match a fuzzy query? their~, in the /select request below, is literally a FuzzyQuery, and ends up matching the document indexed (based on string edit distance fuzziness), rows=0 so we just see the numFound and debug=query output:
$ curl 'http://localhost:8983/solr/playground/select?q=their~&wt=ruby&indent=on&rows=0&debug=query'
{
'responseHeader'=>{
'status'=>0,
'QTime'=>0,
'params'=>{
'q'=>'their~',
'debug'=>'query',
'indent'=>'on',
'rows'=>'0',
'wt'=>'ruby'}},
'response'=>{'numFound'=>1,'start'=>0,'docs'=>[]
},
'debug'=>{
'rawquerystring'=>'their~',
'querystring'=>'their~',
'parsedquery'=>'_text_:their~2',
'parsedquery_toString'=>'_text_:their~2',
'QParser'=>'LuceneQParser'}}
Have fun with your own troublesome text, simply using an id field and any/all fields involved in your test queries, and quickly get some insight into how documents are indexed, text analyzed, and queries match. You can use this CSV trick for testing out a variety of scenarios, including complex faceting, grouping, highlighting, etc often with just a small bit of representative CSV data.
Windows, I’m sorry. But don’t despair.
bin/post is a Unix shell script. There’s no comparable Windows command file, like there is for
bin/solr. The developer of
bin/post is a grey beard Unix curmudgeon and scoffs “patches welcome” when asked where the Windows version is. But don’t despair, before there was
bin/post there was
post.jar. And there still is
post.jar. See the
Windows support section of the Reference Guide for details on how to run the equivalent of everything
bin/post can do.
Future
What more could you want out of a tool to post content to Solr? Turns out a lot! Here’s a few ideas for improvements:
- For starters, SolrCloud support is needed. Right now the exact HTTP end-point is needed, whereas SolrCloud indexing is best
done with ZooKeeper awareness. Perhaps this fits under SOLR-7268.
- SOLR-7057: Better content-type detection and handling (.tsv files could be considered delimited with separator=%09 for example)
- SOLR-6994: Add a comparable Windows command file
- SOLR-7042: Improve bin/post’s arbitrary JSON handling
- SOLR-7188: And maybe, just maybe, this tool could also be the front-end to client-side Data Import Handler
And no doubt there are numerous other improvements to streamline the command-line syntax and hardiness of this handy little tool.
Conclusion
$ bin/post -c your_collection your_data/
No, bin/post is not necessarily the “right” way to get data into your system considering streaming Spark jobs, database content, heavy web crawling, or other Solr integrating connectors. But pragmatically maybe it’s just the ticket for sending commit/delete commands to any of your Solr servers, or doing some quick tests. And, say, if you’ve got a nightly process that produces new data as CSV files, a cron job to
bin/post the new data would be as pragmatic and “production-savvy” as anything else.
Next up…
With bin/post, you’ve gotten your data into Solr in one simple, easy-to-use command. That’s an important step, though only half of the equation. We index content in order to be able to query it, analyze it, and visualize it. The next article in this series delves into Solr’s templated response writing capabilities, providing a typical (and extensible) search results user interface.
The post Solr 5’s new ‘bin/post’ utility appeared first on Lucidworks.