Polaroid is a good example of why even forward thinking companies must achieve agility to meet market needs. We have some suggestions for how to go about the process.
In 1991, Polaroid was a $3 billion company. In 2001, it went bankrupt, eventually selling its brand and assets. The successor company again filed for bankruptcy in 2008, and was eventually sold to the Impossible Project in 2017. Needless to say, today very little of the instant camera giant remains.
Prynt, a company that makes a device that allows you to print photos directly from your phone, raised $1.5 million on Kickstarter when 64 percent of projects fail to meet funding goals.
How did Polaroid go under when the Prynt initiative clearly shows consumers want the ability to print photos in, well, an instant? And can Polaroid teach us lessons about how important transformation is in an increasingly digital world?
How an Innovator Lost Its Way
As the only real player in the instant photography industry, Polaroid was the best positioned to move into digital photography early. We have the advantage of hindsight, but Polaroid’s failure to do so is even more puzzling because Polaroid had a history of pivoting to serve changing markets, aka transformation.
Founded in the 1930s as a polarization company, it shifted course after World War II to instant photography — and disrupted Kodak’s firm grip on the photography market. The company went on to launch many new products to varying degrees of success. It even went on to offer in the mid- 1990’s a “consumer digital camera, though it wasn’t much differentiated from its competition,” according to Christopher Bonanos in his book “Instant: the Story of Polaroid.”
Polaroid’s half-hearted effort at digital transformation took back seat to its primary business of selling instant film.
Eventually, it was overtaken by firms offering digital images – as distinct from digital cameras. A few short years later, digital cameras became all but obsolete when battery life and storage advances turned every phone into a digital camera.
And today we’ve come full circle – the new Polaroid launched an instant print camera in 2015, just after Prynt launched its Kickstarter campaign.
Given the success of digital images, it seems likely that true digital transformation would have helped Polaroid. But just what is true digital transformation?
Digital Transformation Makes the Most of Data
Digital transformation is about finding ways to use data to drive efficiency, business insights, and revenue. And by data we mean internal data: customers data, buying behaviors, market penetration, and external data: market data, trend data, consumer data. Consequently, this pool of data would be unique to every organization.
This pool so to speak faces some challenges within organizations themselves. Those include difficulties managing, integrating, and analyzing enormous amounts of data; resistance to change within organizations; and lack of technologies that make changing direction difficult. The lack of enthusiasm to cannibalize a cash cow as evidenced by Polaroid is frustratingly common. (You can read more about these challenges and ways to overcome them in our previous blog, “Digital Transformation: What We Can Learn From the Experts.“)
Even with these challenges, Gartner estimates that digital transformation projects could account for 36 percent of total corporate revenue by 2020, according to ITPro.
So where and how do you start?
Digital Transformation Journey
You start by creating a new data-driven vision for the organization that helps define new business possibilities and opportunities. You implement changes iteratively, the better to see how changes impact the enterprise. The end goal is agility — the ability to respond to external and internal forces to remain a healthy organization.
![]()
Insights Derived From Data Direct Business Change
Digital transformation thrives on insights derived from data that, in turn, provide a new perspective into business activity and that allows creation of new business models. Insights are distilled from data in context. Insights back up a hypothesis. Data is a raw material.
Had Polaroid found data insights, it might have survived, and Business Insider wouldn’t have called Prnyt, the $150 case that “turns your iPhone into a Polaroid.”
Polaroid knew its highest profit margin was on instant film, but data insights may have given Polaroid’s leaders a new view on the profitability of its inkjet printer business – especially since “printer ink costs more than blood by volume and more than caviar by weight,” according to The Motley Fool.
Key question: Are you systematically looking for and creating new forms of insights?
To promote digital transformation, the insights dimension needs more data, more tools for analytics, faster cycle times for analysis, and more automation of data preparation and data engineering tasks. These are the raw materials of insights.
Awareness of Business Opportunities Can Drive Transformation
Awareness of business challenges and new opportunities comes from applying data insights to a larger section of the enterprise to see a richer view of the world.
Those insights can be the foundation for more complex and richer data models that, through analysis and visualization, allow us to see how events are connected and the choices that we can make.
If Polaroid had the awareness of the market they may have seen that the ability to create as many memories as possible would outweigh the need to have single snapshot of events — or 10 photos of one event.
In 2001, we were just three years away from the founding of Facebook, but social media was already widespread (MySpace anyone?). Polaroid’s leaders may even have foreseen that such spaces would provide permanent electronic records accessible from anywhere.
Key question: What types of new awareness are essential in your program of digital transformation?
To create awareness, organizations need better tools for modeling and exploring data, as well as interactive and automated analysis of it. The ability to find relevant data, create models models, generate reports, and use interactive environments is crucial.
The more the actions taken to serve the customer are digital, the more automation can grow. All of these raw materials create more human awareness but also lay the groundwork for autonomous systems.
Optimization Creates Value Across the Business
Digital transformation programs are iterative. Insights leads to awareness, and awareness leads to new business models. Those, in turn, should be implemented in stages, ideally with a small project that proves the product/market fit of the new digital model.
Optimization expands this nugget into a larger system that creates much more value.
This process continues until the central business model that drives digital transformation expands and adapts to all relevant situations.
In addition, the details of each new application must be taken into account so that the product or service provides maximum value.
Polaroid’s approach to bringing new products to market in the mid-1990’s was “a throw-it-against-the-wall-and-see-what-sticks strategy,” Bonanos wrote. He also noted that Polaroid could have abandoned the consumer digital business and focus on commercial applications such as medical imaging, identification systems, and scientific work. “There, Polaroid could dig into its knowledge base and beat everyone else to market with specialized digital products.”
Digital transformations often lead to unexplored territory that requires that the product keep evolving. The challenge is both moving in the right direction and also moving fast. If Polaroid had optimized its already-existing superior imaging technology into digital images, it may have avoided bankruptcy.
![]()
Key question: What adjustments and optimizations will be needed as your digital business model expands?
Functionality that supports optimization includes the ability to do statistically mature A/B testing and other forms of experimentation including exploring new data sources and formats. Companies need a strong data foundation to analyze and track usage of a product, as well as strong product management to allow collaboration about ideas moving a product forward.
Automation Allows Digital Business Models to Scale
Regardless of industry, the digital age means representing your product, service or process — digitally. Sometimes known as a digital twin, the concept is born out of the Internet of Things and Manufacturing 4.0. While it is possible for a business to grow strictly based on optimized processes, automation enables scalability in the longer term.
In Polaroid’s case, it had manufactured the digital camera, for both commercial and consumer purposes. But it hadn’t considered that people wanted a digital image. If only Polaroid had allowed others to make a digital twin of themselves!
We will look more at the role of the digital twin in the future. But in the meantime, companies that are embarking on it (ranging from healthcare, to media, to automotive) are finding that full automation is hard to achieve and usually involves refactoring business processes into a new architecture. What happens faster is human-guided automation that operates within guard rails so that people can direct the process .
Automation used to be about APIs and coding, and, of course, it still is. But increasingly, automation is powered by machine learning algorithms that can discover and recognize patterns that humans cannot.
Key question: What is your strategy for creating an automation architecture for your digital business model?
The functional landscape for automation must include as much coverage of the product by APIs as possible. This allows scripts, more advanced programs, and machine learning systems to control the behavior of the product or supporting system. As much instrumentation at all levels should be in place to support feedback loops to enable learning and problem solving.
Scalable Architecture Can Grow
Scalability of digital operations is an essential component of digital transformation. It allows the enterprise to build on the iterative successes they achieve and makes optimization possible. (Digital transformation does not always involve massive scale, though it often does.)
Scalable architecture can be built in stages, too. We often think of scalability as one that can expand, and even contract, when needed. For example, Amazon Web Services offers auto scaling, which adjusts when you need more performance.
But it can also mean that “the architecture can natively handle such growth, or that enlarging the architecture to handle growth is a trivial part of the original design,” according to Computer Hope.
It is not required to have the ultimate architecture for scalability at the beginning of digital transformation, but you must plan for growth.
Key question: Is your current architecture scalable for the current stage? Are there signs it is wearing out?
Scalability is not a one-size-fits all solution, rather, each need may require different hardware, software, expertise, and data.
For some technology, it is possible to buy scalable components. For others, the scalability must come by identifying bottlenecks and putting in the right abstractions so that load balancing and scale out approaches can be introduced when needed.
Digital transformation requires that scalability requirements always be present in the minds of the implementers.
Agility Completes Digital Transformation
The hallmark of the most successful digital businesses is the preservation of agility even as the businesses grow. “Agility is the ability of an organization to renew itself, adapt, change quickly, and succeed in a rapidly changing, ambiguous, turbulent environment,” said Aaron De Smet of McKinsey.
For many organizations, agility is the goal of digital transformation. Organizations today are operating in an ever-changing technology environment. To operate successfully when enormous change is happening outside of the enterprise requires agility.
Finding new uses for data and new insights from that data help create growth and stability – even under pressure.
Polaroid was not able to respond effectively to change in the marketplace even though it had some real advantages in the imaging and even printing worlds. It had a reputation for good commercial products and the company was known for investing in research. Yet, with all of these advantages, it did not capitalized on its early knowledge of digital cameras, nor did its leaders realize that the appetite for digital images was endless.
A digital transformation would have allowed Polaroid to adapt to external marketplace forces.
Evelyn L. Kent is a content analytics consultant who specializes in building semantic models. She has 20 years of experience creating, producing and analyzing content for organizations such as USA Today, Tribune and McClatchy.
The post How to Form Your Digital Transformation Strategy appeared first on Lucidworks.





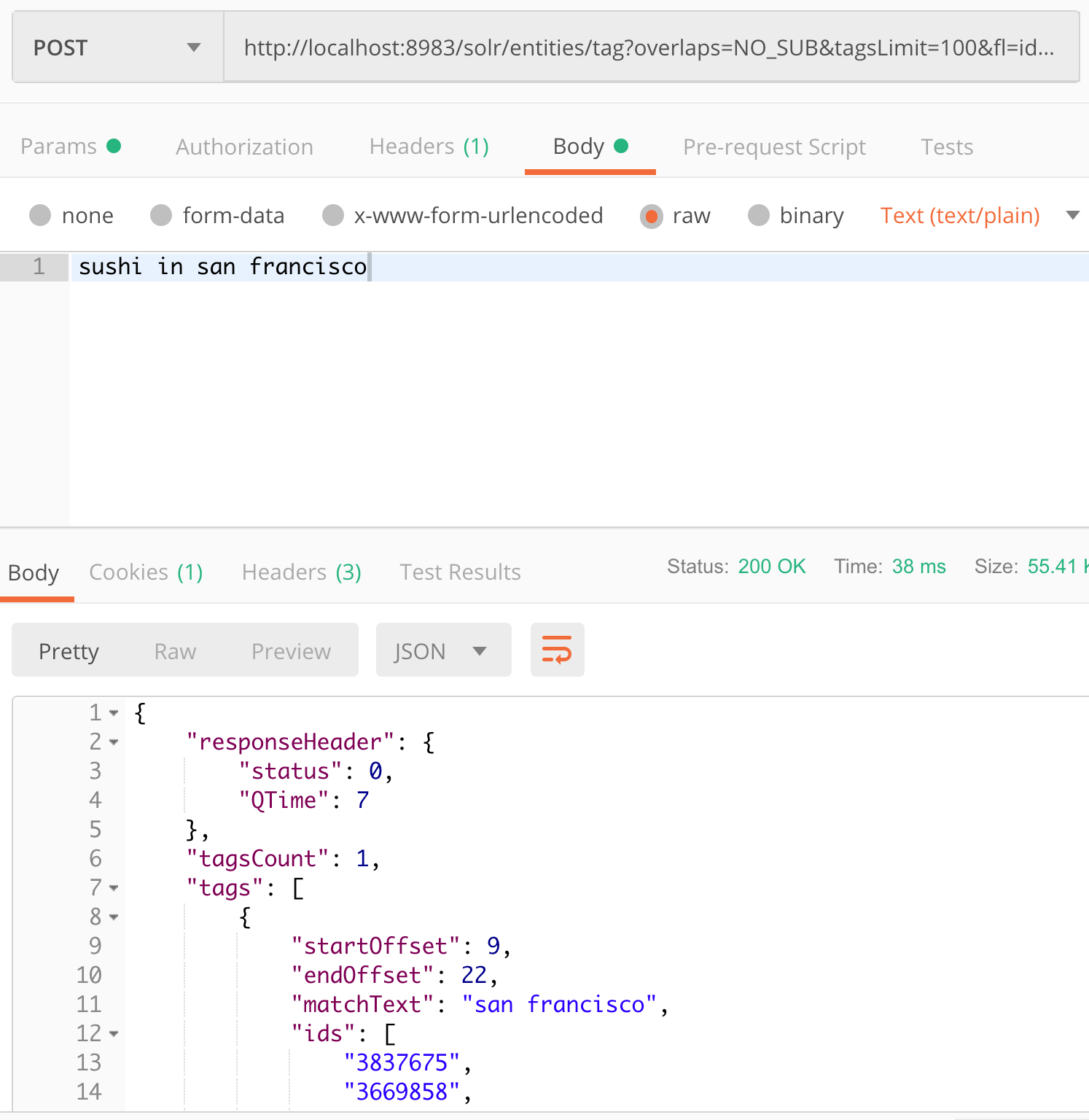
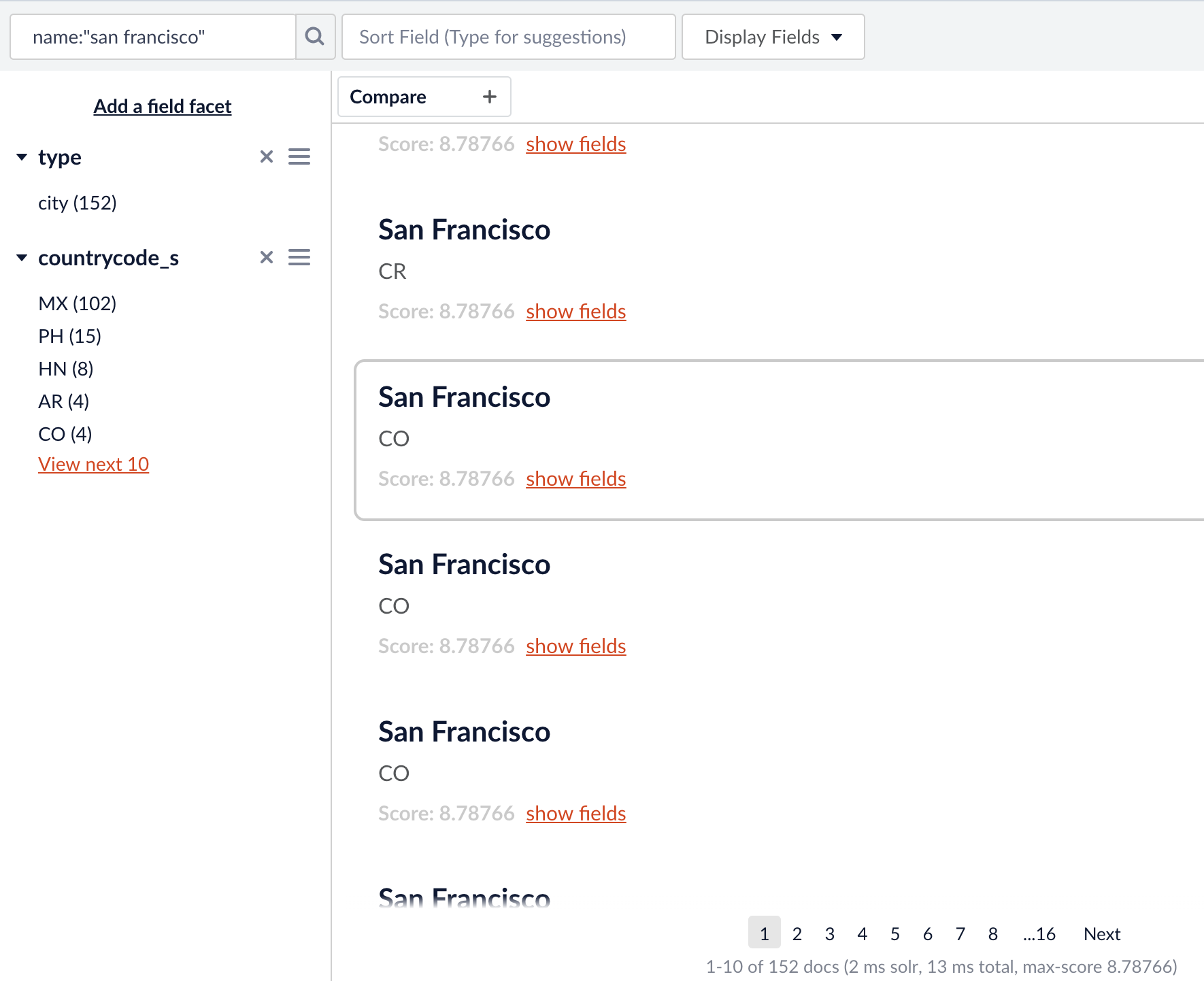














 .
.