As we countdown to the annual Lucene/Solr Revolution conference in Las Vegas next month, we’re highlighting talks and sessions from past conferences. Today, we’re highlighting Target’s Howard Wan’s talk, “Using A Query Classifier To Dynamically Boost Solr Ranking”.
About 40% of our queries at Target.com are ambiguous, which can result in products from many categories. For example, the query “red apple” can match the following products: a red apple ipod (electronic category), red apple fruit ( fresh produce ), red apple iphone case ( accessories). It is desirable to have a classifier to instruct Solr to boost items from the desire category. In addition, for a search engine with a small index, a good percentage of the queries may have little or no results. Is it possible to use the classifier to solve both problems? This talk discusses a classifier built from behavior data which can dynamically re-classify the query to solve both problems.
Join us at Lucene/Solr Revolution 2017, the biggest open source conference dedicated to Apache Lucene/Solr on September 12-15, 2017 in Las Vegas, Nevada. Come meet and network with the thought leaders building and deploying Lucene/Solr open source search technology. Full details and registration…
As we countdown to the annual Lucene/Solr Revolution conference in Las Vegas next month, we’re highlighting talks and sessions from past conferences. Today, we’re highlighting Sony Interactive Entertainment’s Alexander Filipchik’s talk, “PlayStation and Lucene: Indexing 1M Docs per Second on 18 Servers”.
PlayStation4 is a not just a gaming console. The PlayStation Network is a system that handles more than 70 millions active users, and in order to create an awesome gaming experience has to support personalized search at scale. The systems that provide this personalized experience indexes up to 1M documents per second using Lucene and only uses 18 mid sized Amazon instances. This talk covers how the PlayStation team personalizes search for their users at scale with Lucene.
Join us at Lucene/Solr Revolution 2017, the biggest open source conference dedicated to Apache Lucene/Solr on September 12-15, 2017 in Las Vegas, Nevada. Come meet and network with the thought leaders building and deploying Lucene/Solr open source search technology. Full details and registration…
Lucidworks Fusion uses a data pipeline paradigm for both data ingestion (Index Pipelines) and for search (Query Pipelines). A Pipeline consists of one or more ordered Pipeline Stages. Each Stage takes input from the previous Stage and provides input to the following Stage. In the Index Pipeline case, the input is a document to be transformed prior to indexing in Apache Solr.
In the Query Pipelines case, the first stages manipulate a Query Request. A middle stage submits the request to Solr and the following stages can be used to manipulate the Query Response.
The out-of-the-box stages included in Lucidworks Fusion let the user perform many common tasks such as field mapping for an Index Pipeline or specialized Facet queries for the Query Pipeline. However, as described in a previous article, many projects have specialized needs in which the flexibility of the JavaScript stage is needed.
Taking JavaScript to the Next Level with Shared Scripts, Utility Functions and Unit Tests
Throwing a few scripts into a pipeline to perform some customized lookups or parsing logic is all well and good, but sophisticated ingestion strategies could benefit from some more advanced techniques.
Reduce maintenance problems by reusing oft-needed utilities and functions. Some of the advanced features of the Nashorn JavaScript engine largely eliminate the need to copy/paste code into multiple Pipelines. Keeping a single copy reduces code maintenance problems.
Use a modern IDE for editing. The code editor in Fusion is functional but it provides little help with code completion, syntax highlighting, identifying typos illuminating global variables or generally speeding development.
Use Unit Tests to help reduce bugs and ensure the health of a deployment.
Reusing Scripts
Lucidworks Fusion uses the standard Nashorn JavaScript engine which ships with Java 8. The load() command, combined with an Immediately Invoked Function Expression (IIFE) allows a small pipeline script to load another script. This allows common functionality to be shared across pipelines. Here’s an example:
var loadLibrary = function(url){
var lib = null;
try{
logger.info('\n\n*********\n*Try to library load from: ' + url);
lib = load(url);// jshint ignore:line
logger.info('\n\n**********\n* The library loaded from: ' + url);
}catch(e){
logger.error('\n\n******\n* The script at ' + url + ' is missing or invalid\n’ + e.message);
}
return lib;
};
Get Help From an IDE
Any sort of JavaScript function or objects could be contained in the utilLib.js as shown above. Below is a simple example of a library containing two handy functions.
Explanatory notes:
The wrapping structure i.e. (function(){…}).call(this); makes up the IIFE structure used to encapsulate the util object. While this is not strictly necessary, it provides a syntax easily understood by the IntelliJ IDE.
The globals comment at the top, as well as the jshint comment at the bottom, are hints to the JSHint code validation engine used in the IDE. These suppress error conditions resulting from the Nashorn load() functionality and global variables set by the Java environment which invokes the JavaScript Pipeline Stage.
The IDE will have underlined potentially illegal code in red. The result is an opportunity to fix typos without having to repeatedly test-load the script and hunt thru a log file only to find a cryptic error message from the Nashorn engine. Also, note the use of the “use strict” directive. This tells JSHint to also look for things like the inadvertent declaration of global variables.
/* globals Java,arguments*/
(function(){
"use strict";
var util = {};
util.isJavaType = function(obj){
return (obj &&
typeof obj.getClass === 'function' &&
typeof obj.notify === 'function' &&
typeof obj.hashCode === 'function');
}
/**
* For Java objects, return the short name,
* e.g. 'String' for a java.lang.String
*
* JavaScript objects, usually use lower case.
* e.g. 'string' for a JavaScript String
*
*/
util.getTypeOf = function getTypeOf(obj){
'use strict';
var typ = 'unknown';
//test for java objects
if( util.isJavaType(obj)){
typ = obj.getClass().getSimpleName();
}else if (obj === null){
typ = 'null';
}else if (typeof(obj) === typeof(undefined)){
typ = 'undefined';
}else if (typeof(obj) === typeof(String())){
typ = 'string';
}else if (typeof(obj) === typeof([])) {
typ = 'array';
}
else if (Object.prototype.toString.call(obj) === '[object Date]'){
typ = 'date';
}else {
typ = obj ? typeof(obj) :typ;
}
return typ;
};
//return util to make it publicly accessible
return util;
}).call(this); // jshint ignore: line
Overview of Utility Functions
Here is a summary description of some of the utility functions included in utilLib.js
index.concatMV(doc, fieldName, delim) Return a delimited String containing all values for a given field. If the names field contains values for ‘James’, ‘Jim’, ‘Jamie’, and ‘Jim’, calling index.concatMV(doc, ‘names’, ‘, ‘) would return “James, Jim, Jamie”
index.getFieldNames(doc, pattern) Return an array of field names in doc which match the pattern regular expression.
index.trimField(doc, fieldName) Remove all whitespace from all values of the field specified. Leading and trailing whitespace is truncated and redundant whitespace within values is replaced with a single space.
util.concat(varargs) Here varargs can be one or more arguments of String or String[]. They will all be concatenated into a single String and returned.
util.dateToISOString(date) Convert a Java Date or JavaScript Date into an ISO 8601 formatted String.
util.dedup(arr) Remove redundant elements in an array.
util. decrypt(toDecrypt) Decrypt an AES encrypted String.
util. encrypt(toEncrypt) Encrypt a string with AES encryption.
util. getFusionConfigProperties() Read in the default Fusion config/config.properties file and return it as a Java Properties object.
util.isoStringToDate(dateString) Convert an ISO 8601 formatted String into a Java Date.
util. queryHttp2Json(url) Perform an HTTP GET on a URL and parse the response into JSON.
util.stripTags(markupString) Remove markup tags from an HTML or XML string.
util.truncateString(text, len, useWordBoundary) Truncate text to a length of len. If useWordBoundary is true break on the word boundary just before len.
Testing the Code
Automated unit testing of Fusion stages can be complicated. Unit testing shared utility functions intended for use in Fusion stages is even more difficult. A full test harness is beyond the scope of this Blog, but the essentials can be accomplished with the command-line curl utility or an REST client like Postman.
Start with a well-known state in the form of a pre-made PipelineDocument. To see an example of the needed JSON, look at what is produced by the Logging Stage which comes with Fusion.
POST the PipelineDocument Fusion using the Index Pipelines API. You will need to pass an ID, and Collection name as parameters as well as the trailing “/index” path in order to invoke the pipeline.
The POST operation should return the document as modified by the pipeline. Inspect it and signal Pass or Fail events as needed.
Unit tests can also be performed manually by running the Pipeline within Fusion. This could be part of a Workbench simulation or an actual Ingestion/Query operation. The utilLib.js contains a rudimentary test harness for executing tests and comparing the results to an expected String value. The results of tests are written both to the connections.log or api.log as well as being pushed into the Stage’s context map in the _runtime_test_results element as shown below. The first test shows that util.dedup(‘a’, ‘b’, ‘c’, ‘a’, ‘b’) but the results do not contain the duplicates. Other common tests are also performed. For complete details see the index.runTests() function in utilLib.js.
Summary
This article demonstrates how to load shareable JavaScript into Fusion’s Pipeline Stages so that common functions can be shared across pipelines. It also contains several handy utility functions which can be used as-is or as a building blocks in more complex data manipulations. Additionally, ways to avoid common pitfalls such as JavaScript syntax typos and unintended global variables were shown. Finally, a Pipeline Simulation was run and the sample unit-test results were shown.
Acknowledgements
Special thanks to Carlos Valcarcel and Robert Lucarini of Lucidwoks as well as Patrick Hoeffel and Matt Kuiper at Polaris Alpha for their help and sample scripts.
It’s that time of the year again – time for our fourth annual survey of the Solr marketplace and ecosystem. Every day, we hear from organizations looking to hire Solr talent. Recruiters want to know how to find and hire the right developers and engineers, and how to compensate them accordingly.
Lucidworks is conducting our annual global survey of Solr professionals to better understand how engineers and developers at all levels of experience can take advantage of the growth of the Solr ecosystem – and how they are using Solr to build amazing search applications.
This survey will take about 2 minutes to complete. Responses are anonymized and confidential. Once our survey and research is completed, we’ll share the results with you and the Solr community.
As a thank you for your participation, you’ll be entered in a drawing to win one of our “You Autocomplete Me” t-shirts plus copies of the popular books Taming Text and Solr in Action. Be sure to include your t-shirt size in the questionnaire.
In this post, I show you how to train a machine learning model and use it for generating predictions on documents in Fusion 3.1. To keep things simple, I chose to use the “hello world” of machine learning: 20-newsgroups. This allows us to focus on the process of training a model into Fusion without getting lost in the details.
Tip: If you’re not a git user, no problem you can download the project zip file from fusion-spark-bootcamp/master.zip.
cd fusion-spark-bootcamp
Edit the myenv.sh script to set the variables for your environment.
cd labs/ml20news
./setup_ml20news.sh
This lab will
Download the 20-newsgroup dataset
Index documents using a Fusion index pipeline
Define a Spark job for training the model
Run the Spark job.
Define an index pipeline with the ML stage for trained model
Test the index pipeline by indexing test documents
After the setup_ml20news.sh script runs, you will have a Logistic Regression model trained and ready to use in Index pipelines. To see the model in action, send the following request:
curl -u admin:password123 -X POST -H "Content-type:application/json" --data-binary @<(cat <<EOF
[
{
"id":"999",
"ts": "2016-02-24T00:10:01Z",
"body_t": "this is a doc about windscreens and face shields for cycles"
}
]
EOF
) "http://localhost:8764/api/apollo/index-pipelines/ml20news-default/collections/ml20news/index?echo=true"
If you see the following output, then you know the classifier is working as expected.
Now let’s look under the hood to understand how to train and deploy the trained model
Training the Classifier Model
Before we can generate classification predictions during indexing, we need to train a classifier model using our training data. The setup_ml20news.sh script already indexed the 20 newsgroup data from http://qwone.com/~jason/20Newsgroups/
Each indexed document contains fields ‘content_txt’, ‘newsgroup_s’ in which ‘content_txt’ is used for feature extraction and ‘newsgroup_s’ is used as labels for ML training.
Next, we will look at the Spark job that trains on the indexed data and creates a model.
The screenshot below shows the UI for the Spark job that is created by the script. The job defines ‘content_txt’ as the field to vectorize and ‘newsgroup_s’ as the label field to use. The job also defines a model id which will be used to store the trained model in the blob store. The default name of the model is the job id. This can be configured via the job UI.
Running a Fusion ML job runs a Spark job behind the scenes and saves the output model into Fusion blob store. The saved output model can be used later at query or index time. Fusion ML job output shows counters for the number of labels it trained on.
When the job is finished, the ML model is accessible from the Fusion blob store.
Generating Predictions Using a Trained Model
After the model is trained through a Spark job, it can be used in both query and index pipelines. In this example, I will show how to use it in an index pipeline to generate predictions on documents before they are indexed.
The index pipeline is configured with an ML stage that is configured to take input field ‘body_t’ and output the prediction into a new field ‘the_newsgroup_s’. The model id in the stage should be the trained model name. (By default, this is the name of the Spark job that trained the model)
Fusion connectors can be used to index data from over 40 data sources and if these datasources are configured to use the index pipeline with the ML stage, then the predictions will be generated on all the documents that are indexed. The example below shows the use of index workbench to index documents and generate predictions. Here, I am trying to index a JSON file with 5 test documents and after the job finishes, the field ‘the_newsgroup_s’ is added to all the 5 documents.
As we countdown to the annual Lucene/Solr Revolution conference in Las Vegas next month, we’re highlighting talks and sessions from past conferences. Today, we’re highlighting Dice.com’s Simon Hughes’ talk, “Evolving the Optimal Relevancy Scoring Model at Dice.com”.
A popular conference topic in recent years is using machine learned ranking (MLR) to re-rank the top results of a Solr query to improve relevancy. However, such approaches fail to first ensure that they have the optimal query configuration for their search engine, without which the re-ranked results may fail to contain the most relevant items for each query (lowering recall). Solr offers many configuration options to control how documents are ranked and scored in terms of relevancy to a user’s query, including what boosts to assign to each field, and how strongly to boost phrasal matches. It is common for companies to manually tune these parameters to optimize relevancy, but this process is highly subjective and not guaranteed to produce the optimal results. We will show a data-driven approach to relevancy tuning that uses optimization algorithms, such as evolutionary algorithms, to evolve a query configuration that optimizes the relevancy of the results returned using data captured from our query logs. We will also discuss how we experimented with evolving a custom similarity algorithm to out-perform BM25 and tf.idf similarity on our dataset. Finally, we’ll discuss the dangers of positive feedback loops when training machine learned ranking models.
Join us at Lucene/Solr Revolution 2017, the biggest open source conference dedicated to Apache Lucene/Solr on September 12-15, 2017 in Las Vegas, Nevada. Come meet and network with the thought leaders building and deploying Lucene/Solr open source search technology. Full details and registration…
Today, Reddit announced their new search for ‘the front page of the internet’ built with Lucidworks Fusion.
Started back in the halcyon Web 2.0 days of 2005, Reddit has become the fourth most popular site in the US and 9th in the world with more than 300 million users every month posting links, commenting and voting across their 1.1 million communities (called ‘sub-reddits’). Sub-reddits can orbit around such broad mainstream topics as /r/politics, /r/bitcoin, and /r/starwars or as obscure as /r/bunnieswithhats, /r/grilledcheese, and /r/animalsbeingjerks. Search is a key part of trying to find more information on their favorite topics and hobbies across the entire universe of communities.
As the site has grown, the search function has had five different search stacks implemented over the years including Postgres, PyLucene, Apache Solr, IndexTank, and Amazon’s CloudSearch. Each time performance got better but wasn’t keeping up with the pace of the site’s growth and relevancy wasn’t where it should be.
“When you think about the Internet, you think about a handful of sites — Facebook, Google, Youtube, and Reddit. My personal opinion is that Reddit is the most important of all of these,” explained Lucidworks CEO, Will Hayes. “It connects strangers from all over the world around an incredibly diverse group of topics. Content is created at a breakneck pace and at massive scale. Because of this, the search function becomes an incredibly important piece of the UX puzzle. Lucidworks Fusion allows Reddit to tackle the scale and complexity issues and provide the world-class search experience that their users expect. ”
The team chose Lucidworks Fusion for it’s best-in-class search capabilities including efficient scaling, monitoring, and improved search relevance.
“Reddit relies heavily on content discovery, as our primary value proposition is giving our people a home for discovering, sharing, and discussing the things they’re most passionate about,” said Nick Caldwell, Vice President of Engineering at Reddit. “As Reddit has grown, so have our communities’ expectations of the experience we provide, and improving our search platform will help us address a long-time user pain point in a meaningful way. We expect Fusion’s customization and machine learning functionality will significantly elevate our search capabilities and transform the way people discover content on the site.”
Here’s just a few of the results from the new search which is now at 100% availability to all users:
ETL indexing pipelines reduced to just 4 Hive queries, which led to a 33% increase in posts indexed
Full re-index of all of Reddit content slashed from 11 hours to 5 with constant live updates and errors down by two orders of magnitude
Amount of hardware/machines reduced from 200 to 30
99% of queries served search results in 500ms
Comparable relevancy to the old search (without any fine-tuning yet!)
Before we delve into the technical details, what’s the big picture? What real-world challenges are made better with these new Solr capabilities? Here’s some use cases where payloads can help:
per-store pricing
weighted terms, such as the confidence or importance of a term
weighting term types, like factoring synonyms lower, or verbs higher
Now on to the technical details, starting with how payloads are implemented in Lucene, and then to Solr’s integration.
Payloads in Lucene
The heart of Solr is powered by our favorite Java library of all-time, Lucene. Lucene has had this payload feature for a while, but hasn’t seen much light of day partly because until now it hasn’t been supported natively in Solr.
Let’s take a moment to refresh ourselves on how how Lucene works, and then show where payloads fit in.
Lucene Index Structure
Lucene builds an inverted index of the content fed to it. An inverted index is, at a basic level, a straightforward dictionary of words from the corpus alphabetized for easy finding later. This inverted index powers keyword searches handily. Want to find documents with “cat” in the title? Simply look up “cat” in the inverted index, and report all of the documents listed that contain that term – very much like looking up words in the index at the back of books to find the referring pages.
Finding documents super fast based off words in them is what Lucene does. We may also require matching words in proximity to one another, and thus Lucene optionally records the position information to allow for phrase matching, words or terms close to one another. Position information provides the word number (or position offset) of a term: “cat herder” has “cat” and “herder” in successive positions.
For each occurrence of an indexed word (or term) in a document, the positional information is recorded. Additionally, and also optionally, the offsets (the actual character start and end offset) can be encoded per term position.
Payloads
Available alongside the positionally related information is an optional general purpose byte array. At the lowest-level, Lucene allows any term in any position to store whatever bytes it’d like in its payload area. This byte array can be retrieved as the term’s position is accessed.
These per-term/position byte arrays can be populated in a variety of ways using some esoteric built-in Lucene TokenFilter‘s, a few of which I’ll de-cloak below.
A payload’s primary use case is to affect relevancy scoring; there are also other very interesting ways to use payloads, discussed here later. Built-in at Lucene’s core scoring mechanism is float Similarity#computePayloadFactor() which until now has not been used by any production code in Lucene or Solr; though to be sure, it has been exercised extensively within Lucene’s test suite since inception. It’s hardy, just under-utilized outside custom expert-level coding to ensure index-time payloads are encoded the same way they are decoded at query time, and to hook this mechanism into scoring.
Payloads in Solr
One of Solr’s value-adds is providing rigor to the fields and field types used, keeping index and query time behavior in sync. Payload support followed along, linking index-time payload encoding with query time decoding through the field type definition.
The payload features described here were added to Solr 6.6, tracked in SOLR-1485.
Let’s start with an end-to-end example…
Solr|6.6 Payload Example
Here’s a quick example of assigning per-term float payloads and leveraging them:
If that last command gives you any trouble, navigate to <http://localhost:8983/solr/#/payloads/documents>, change the `Document Type` to CSV, and paste this CSV into the “Document(s)” area:
Two documents are indexed (id 1 and 2) with a special field called vals_dpf. Solr’s default configuration provides *_dpf, the suffix indicating it is of “delimited payloads, float” field type.
Let’s see what this example can do, and then we’ll break down how it worked.
The payload() function returns a float computed from the numerically encoded payloads on a particular term. In the first document just indexed, the term “one” has a float of 1.0 encoded into its payload, and likewise “two” with the value of 2.0, “three” with 3.0. The second document has the same term, “weighted” repeated, with a different (remember, payloads are per-position) payload for each of those terms’ positions.
Solr’s pseudo-fields provide a useful way to access payload function computations. For example, to compute the payload function for the term “three”, we use payload(vals_dpf,three). The first argument is the field name, and the second argument is the term of interest.
The first document has a term “three” with a payload value of 3.0. The second document does not contain this term, and the payload() function returns the default 0.0 value.
Using the above indexed data, here’s an example that leverages all the various payload() function options:
There’s a useful bit of parameter substitution indirection to allow the field name to be specified as f=vals_dpf once and referenced in all the functions. Similarly, the term weighted is specified as the query parameter t and substituted in the payload functions.
Note that this query limits to q=id:2 to demonstrate the effect with multiple payloads involved. The fl expression def:payload($f,not_there,37) finds no term “not_there” and returns the specified fall-back default value of 37.0, and avg:payload($f,$t,0.0,average) takes the average of the payloads found on all the positions of the term “weighted” (50.0 and 100.0) and returns the average, 75.0.
Indexing terms with payloads
The default (data_driven) configuration comes with three new payload-using field types. In the example above, the delimited_payloads_float field type was used, which is mapped to a *_dpf dynamic field definition making it handy to use right away. This field type is defined with a WhitespaceTokenizer followed by a DelimitedPayloadTokenFilter. Textually, it’s just a whitespace tokenizer (case and characters matter!). If the token ends with a vertical bar (|) delimiter followed a floating point number, the delimiter and number are stripped from the indexed term and the number encoded into the payload.
Solr’s analysis tool provides introspection into how these delimited payloads field types work. Using the first document in the earlier example, keeping the output simple (non-verbose), we see the effect of whitespace tokenization followed by delimited payload filtering, with the basic textual indexing of the term being the base word/token value, stripping off the delimiter and everything following it. Indexing-wise, this means the terms “one”, “two”, and “three” are indexed and searchable with standard queries, just as if we had indexed “one two three” into a standard text field.
delimited payloads, float – analysis terms
Looking a little deeper into the indexing analysis by turning on verbose view, we can see in the following screenshot a hex dump view of the payload bytes assigned to each term in the last row labeled “payload”.
delimited payloads, float – verbose analysis
Payloaded field types
These new payloaded field types are available in Solr’s data_driven configuration:
field type
payload encoding
dynamic field mapping
delimited_payloads_float
float
*_dpf
delimited_payloads_int
integer
*_dpi
delimited_payloads_string
string, as-is
*_dps
Each of these is whitespace tokenized with delimited payload filtering, the difference being the payload encoding/decoding used.
payload() function
The payload() function, in the simple case of unique, non-repeating terms with a numeric (integer or float) payload, effectively returns the actual payload value. When the payload() function encounters terms that are repeated, it will either take the first value it encounters, or iterate through all of them returning the minimum, maximum, or average payload value.
where the defaults are 0.0 for the default value, and for averaging the payload values.
Back to the Use Cases
That’s great, three=3.0, and the average of 50.0 and 100.0 is 75.0. Like we needed payloads to tell us that. We could have indexed a field, say words_t with “three three three” and done termsfreq(words_t,three) and gotten 3 back. We could have fields min_f set to 50.0 and max_f set to 100.0 and used div(sum(min_f,max_f),2) to get 75.0.
Payloads give us another technique, and it opens up some new possibilities.
Per-store Pricing
Business is booming, we’ve got stores all across the country! Logistics is hard, and expensive. The closer a widget is made to the store, the less shipping costs; or rather, it costs more for a widget the further it has to travel. Maybe not so contrived rationale aside, this sort of situation with per-store pricing of products is how it is with some businesses. So, when a customer is browsing my online store they are associated with their preferred or nearest physical store, where all product prices seen (and faceted and sorted don’t forget!) are specific to the pricing set up for that store for that product.
Let’s whiteboard that one out and be pragmatic about the solutions available: if you’ve got five stores, maybe have five Solr collections even with everything the same but the prices? What if there are 100 stores and growing, managing that many collections becomes a whole new level of complexity, so then maybe have a field for each store, on each product document? Both of those work, and work well…. to a point. There are pro’s and con’s to these various approaches. But what if we’ve got 5000 stores? Things get unwieldy with lots of fields due Solr’s caching and per-field machinery; consider one user from each store region doing a search with sorting and faceting, multiplying a traditional numeric sorting requirement times 5000. Another technique that folks implement is to cross products with stores and have a document for every store-product, which is similar to a collection per store but very quickly explodes to lots of documents (num_stores * num_products can be a lot!). Let’s see how payloads gives us another way to handle this situation.
Create a product collection with bin/create -c products and then CSV import the following data; using the Documents tab in CSV mode is easiest, paste in this and submit:
I stuck with dynamic field mappings to keep things working easily out of the box in this example, but I’d personally use cleaner names for real such as default_price instead of default_price_fandstore_prices instead of store_prices_dpf.
In Alaska, though, that’s not the correct sort order. Let’s associate the request with STORE_AK, using &store_id=STORE_AK, and see the computed price based on the payload associated with the store_id for each product document with &computed_price=payload(store_prices_dpf,$store_id,default_price_f). Note that those two parameters are ours, not Solr’s. With a function defined as a separate parameter, we can re-use it where we need it. To see the field, add it to fl with &fl=actual_price:${computed_price}, and to sort by it, use &sort=${computed_price} asc.
Circling back to the approaches with per-store pricing as if we had 5000 stores. 5000*number_of_products documents versus 5000 collections versus 5000 fields versus 5000 terms. Lucene is good at lots of terms per field, and with payloads along for the ride it’s a good fit for this many-value-per-document scenario.
Faceting on numeric payloads
Faceting is currently a bit trickier with computed values, since facet.range only works with actual fields not pseudo ones. In this price case, since there aren’t usually many price ranges needed we can use facet.query‘s along with {!frange} on the payload(). With the example data, let’s facet on (computed/actual) price ranges. The following two parameters define two price ranges:
Here’s the price range facet output with store_id=STORE_AK:
facet_queries: {
up_to_400: 2,
above_400: 0
}
Weighted terms
This particular use case is implemented exactly as the pricing example, using whatever terms appropriate instead of store identifiers. This could be, for example, useful for weighting the same words differently depending on the context in which they appear – words being parsed into an <H1> html tag could be assigned a payload weight greater than other terms. Or perhaps during indexing, entity extraction can assign confidence weights about the confidence of the entity choice.
To assign payloads to terms using the delimited payload token filtering, the indexing process will need to craft the terms in the “term|payload” delimited fashion.
Synonym weighting
One technique many of us have used is the two-field copyField trick where one field has synonyms enabled, and another without synonym filtering, and using query fields (edismax qf) to weight the non-synonym field higher than the synonym field allowing closer to exact matches a relevancy boost.
Instead, payloads can be used to down-weight synonyms within a single field. Note this is an index-time technique with synonyms, not query-time. The secret behind this comes from a handy analysis component called NumericPayloadTokenFilterFactory – this handy filter assigns the specified payload to all terms matching the token type specified, “SYNONYM” in this case. The synonym filter injects terms with this special token type value; token type is generally ignored and not indexed in any manner, yet being useful during the analysis process to key off of for other operations like this trick of assigning a payload to only certain tagged tokens.
For demonstration purposes, let’s create a new collection to experiment with: bin/solr create -c docs
There’s no built-in field type that has this set up already, so let’s add one:
With that field, we can add a document that will have synonyms assigned (the out of the box synonyms.txt contains Television, Televisions, TV, TVs), again adding it through the Solr admin Documents area, for the docs collection just created using Document Type CSV:
Changing &payload_term=television reduces the score to 0.1.
This term type to numeric payload mapping can be useful beyond synonyms – there are a number of other token types that various Solr analysis components can assign, including <EMAIL> and <URL>tokens that UAX29URLEmailTokenizer can extract.
Payload-savvy query parsers
There are two new query parsers available that leverage payloads, payload_score and payload_check. The following table details the syntax of these parsers:
query parser
description
specification
{!payload_score}
SpanQuery/phrase matching, scores based on numerically encoded payloads attached to the matching terms
SpanQuery/phrase matching that have a specific payload at the given position, scores based on SpanQuery/phrase scoring
{!payload_check
f=field_name
payloads='...'}
Both of these query parsers tokenize the query string based on the field type’s query time analysis definition (whitespace tokenization for the built-in payload types) and formulates an exact phrase (SpanNearQuery) query for matching.
{!payload_score} query parser
The {!payload_score} query parser matches on the phrase specified, scoring each document based on the payloads encountered on the query terms, using the min, max, or average. In addition, the natural score of the phrase match based off the usual index statistics for the query terms can be multipled into the computed payload scoring factor using includeSpanScore=true.
{!payload_check} query parser
So far we’ve focused on numeric payloads, however strings (or raw bytes) can be encoded into payloads as well. These non-numeric payloads, while not usable with the payload() function intended solely for numeric encoded payloads, they can be used for an additional level of matching.
Let’s add another document to our original “payloads” collection using the *_dps dynamic field to encode payloads as strings:
We’ve now got three terms, payloaded with their part of speech. Using {!payload_check}, we can search for “train” and only match if it was payloaded as “NOUN”:
if instead payloads=VERB, this document would not match. Scoring from {!payload_check} is the score of the SpanNearQuery generated, using payloads purely for matching. When multiple words are specified for the main query string, multiple payloads must be specified, and match in the same order as the specified query terms. The payloads specified must be space separated. We can match “the train” in this example when those two words are, in order, an ARTICLE and a NOUN:
The payload feature provides per-term instance metadata, available to influence scores and provide additional level of query matching.
Next steps
Above we saw how to range facet using payloads. This is less than ideal, but there’s hope for true range faceting over functions. Track SOLR-10541 to see when this feature is implemented.
Just after this Solr payload work was completed, a related useful addition was made to Lucene to allow term frequency overriding, which is a short-cut to the age-old repeated keyword technique. This was implemented for Lucene 7.0 at LUCENE-7854. Like the payload delimiting token filters described above, there’s now also a DelimitedTermFrequencyTokenFilter. Payloads, remember, are encoded per term position, increasing the index size and requiring an additional lookup per term position to retrieve and decode them. Term frequency, however, is a single value for a given term. It’s limited to integer values and is more performantly accessible than a payload. The payload() function can be modified to transparently support integer encoded payloads and delimited term frequency overrides (note: the termfreq() function would work in this case already). Track SOLR-11358 for the status of the transparent term frequency / integer payload() implementation.
Also, alas, there was a bug reported with debug=true mode when using the payload() when assertions are enabled. A fix is on the patch provided at SOLR-10874.
Replica Types – Solr 7 supports different replica types, which handle updates differently. In addition to pure NRT operation where all replicas build an index and keep a replication log, you can now also add so called PULL replicas, achieving the read-speed optimized benefits of a master/slave setup while at the same time keeping index redundancy.
Auto-scaling. Solr can now allocate new replicas to nodes using a new auto scaling policy framework. This framework will in future releases enable Solr to move shards around based on load, disk etc.
Indented JSON is now the default response format for all APIs, pass wt=xml and/or indent=off to use the previous unindented XML format.
The JSON Facet API now supports two-phase facet refinement to ensure accurate counts and statistics for facet buckets returned in distributed mode.
Streaming Expressions adds a new statistical programming syntax for the statistical analysis of sql queries, random samples, time series and graph result sets.
Analytics Component version 2.0, which now supports distributed collections, expressions over multivalued fields, a new JSON request language, and more.
The new v2 API, exposed at /api/ and also supported via SolrJ, is now the preferred API, but /solr/ continues to work.
A new ‘_default’ configset is used if no config is specified at collection creation. The data-driven functionality of this configset indexes strings as analyzed text while at the same time copying to a ‘*_str’ field suitable for faceting.
Solr 7 is tested with and verified to support Java 9.
I just got back from an another incredible Lucene/Solr Revolution, this year in Sin City (aka Las Vegas) Nevada. The problem is that there were so many good talks, that I now can’t wait for the video tape to be put up on U-Tube, because I routinely had to make very difficult choices about which one to see. I was also fortunate to be among those presenting, so my own attempt at cramming well over an hour’s worth of material into 40 minutes will be available for your amusement and hopefully edification as well. In the words of one of my favorite TV comedians from my childhood, Maxwell Smart, I “Missed It by that much”. I ran 4 minutes, 41 seconds over the 40 minutes allotted to be exact. I know this because I was running a stopwatch on my cell phone to keep me from doing just that. I had done far worse in my science career, cramming my entire Ph.D thesis into a 15 minute slide talk at a Neurosciences convention in Cincinnati – but I was young and foolish then. I should be older and wiser now. You would think.
But it was in that week in Vegas that I reached this synthesis that I’m describing here – and since then have refined even a bit more, which is also why I am writing this blog post. When I conceived of the talk about a year ago, the idea was to do a sort of review of some interesting things that I had done and blogged about concerning facets. At the time, there must have been a “theme” somewhere in my head – because I remember having been excited about it, but by the time I got around to submitting the abstract four months later and finally putting the slide deck together nearly a year later, I couldn’t remember exactly what that was. I knew that I hadn’t wanted to do a “I did this cool thing, then I did this other cool thing, etc.” about stuff that I had mostly already blogged about, because that would have been a waste of everyone’s time. Fortunately the lens of pressure to get “something” interesting to say after my normal lengthy period of procrastination, plus the inspiration from being at Revolution and the previous days answers to “So Ted, what is your talk going to be about?” led to the light-bulb moment, just in the nick-of-time, that was an even better synthesis than I had had the year before (pretty sure, but again don’t remember, so maybe not – we’ll never know).
My talk was about some interesting things I had done with facets that go beyond traditional usages such as faceted navigation and dashboards. I started with these to get the talk revved up. I also threw in some stuff about the history of facet technologies both to show my age and vast search experience and to compare the terms different vendors used for faceting. At the time, I thought that this was merely interesting from a semantic standpoint, and it also contained an attempt at humor which I’ll get to later. But with my new post-talk improved synthesis – this facet vocabulary comparison is in fact even more interesting so I am now really glad that I started it off this way (more on this later). I was then planning to launch into my Monty Python “And Now for Something Completely Different” mad scientist section. I also wanted to talk about search and language, which is one of my more predictable soapbox issues. This led up to a live performance of some personal favorite tracks from my quartet of Query Autofilter blogs (1,2,3,4), featuring a new and improved implementation of QAF as a Fusion Query Pipeline Stage (coming soon to Lucidworks Labs) and some new semantic insights gleaned from of my recent eCommerce work for a large home products retailer. I also showed an improved version of the “Who’s In The Who” demo that I had attempted 2 years prior in Austin, based on a cleaner, slicker query patterns (formally Verb Patterns). I used a screenshot for Vegas to avoid the ever present demo gods which had bit me 2 years earlier. I was not worried about the demo per-se with my newly improved and more robust implementation, just boring networking issues and login timeouts and such in Fusion – I needed to be as nimble as I could be. But as I worked on the deck in the week leading up to Revolution – nothing was gelin’ yet.
The Epiphany
I felt that the two most interesting things that I had done with facets were the dynamic boosting typeahead trick from what I like to call my “Jimi Hendrix Blog” and the newer stuff on Keyword Clustering in which I used facets to do some Word-2-Vec’ish things. But as I was preparing to explain these slides – I realized that in both cases, I was doing exactly the same thing at an abstract level!! I had always been talking about “context” as being important – remembering a slide from one of my webinars in which the word CONTEXT was the only word on the slide in bold italic 72 Pt font – a slide that my boss Grant Ingersoll would surely have liked (he had teased me about my well known tendency for extemporizing at lunch before my talk) – I mean, who could talk for more than 2 minutes about one word? As one of my other favorite TV comics from the 60’s and 70’s, Bob Newhart would say – “That … ah … that … would be me”. (but actually not in this case – I timed it – but I’m certainly capable of it) Also, I had always thought of facets as displaying some kind of global result-set context that the UI displayed.
I had also started the talk with a discussion about facets and metadata as being equivalent, but what I realized is that my “type the letter ‘J’ into typeahead, get back alphabetical stuff starting with ‘J’ then search for “Paul McCartney”, then type ‘J’ again and get back ‘John Lennon’ stuff on top” and my heretically mad scientist-esque “facet on all the tokens in a big text field, compute some funky ratios and of the returned 50,000 facet values for the ‘positive’ and ‘negative’ queries for each term and VOILA get back some cool Keyword Clusters” examples were based ON THE SAME PRINCIPAL!!! You guessed it “context”!!!
So, what do we actually mean by “context”?
Context is a word we search guys like to bandy around as if to say, “search is hard, because the answer that you get is dependent on context” – in other words it is often a hand-waving, i.e. B.S. term for “its very complicated”. But seriously, what is context? At the risk of getting too abstractly geeky – I would say that ‘context’ is some place or location within some kind of space. Googling the word got me this definition:
“the circumstances that form the setting for an event, statement, or idea, and in terms of which it can be fully understood and assessed.”
Let me zoom in on “setting for an event” as being roughly equivalent to my original more abstract-mathematical PhD-ie (pronounced “fuddy”) “space” notion. In other words, there are different types of context – personal, interpersonal/social/cultural, temporal, personal-temporal (aka personal history), geospatial, subject/categorical and you can think of them as some kind of “space” in which a “context” is somewhere within that larger space – i.e. some “subspace” as the math and Star Trek geeks would say (remember the “subspace continuum” Trek fans?) – I love this geeky stuff of course, but I hope that it actually helps ‘splain stuff too … The last part “in terms of which is can be fully understood and assessed” is also key and resonates nicely with the Theorem that I am about to unfold.
In my initial discussion on facets as being equivalent to metadata, the totality of all of the facet fields and their values in a Solr collection constitutes some sort of global “meta-informational space”. This led to the recollection/realization that this was why Verity called this stuff “Parametric Search” and led Endeca to call these facet things “Dimensions”. We are dealing with what Math/ML geeks would call an “N-Dimensional hyperspace” in which some dimensions are temporal, some numerical and some textual (whew!). Don’t try to get your head around this – again, just think of it as a “space” in which “context” represents some location or area within that space. Facets then represent vectors or pointers into this “meta-informational” subspace of a collection based on the current query and the collected facet values of the result set. You may want to stop now, get something to drink, watch some TV, take a nap, come back and read this paragraph a few more times before moving on. Or not. But to simplify this a bit (what me? – I usually obfuscate) – lets call a set of facets and their values returned from a query as the “meta-informational context” for that query. So that is what facets do, in a kinda-sorta geeky descriptive way. Works for me and hopefully for you too. In any case, we need to move on.
So, getting back to our example – throw in a query or two and for each, get this facet response which we are now calling the result set’s “meta-informational context” and take another look at the previous examples. In the first case, we were searching for “Paul McCartney” – storing this entity’s meta-informational context and then sending it back to the search engine as a boost query and getting back “John Lennon” related stuff. In the second case, we were searching for each term in the collection, getting back the meta-informational context for that term and then comparing that term’s context with that of all of the other terms that the two facet queries return and computing a ratio, in which related terms have more contextual overlap for the positive than the negative query – so that two terms with similar contexts have high ratios and those with little or no contextual overlap would have low ratio values hovering around 1.0.
Paul McCartney and John Lennon are very similar entities in my Music Ontology and two words that are keywords in the same subject area also have very similar contexts in a subject-based “space” – so these two seemingly different tricks appear to be doing the same thing – finding similar things based on the similarity of their meta-informational contexts – courtesy of facets! Ohhhh Kaaaaay … Cool! – I think we’re on to something here!!
The Facet Theorem
So to boil all of this to an elevator speech – single takeaway slide, I started to think of it as a Theorem in Mathematics – a set of simple, hopefully self-evident assumptions or lemmas that when combined give a cool, and hopefully surprising result. So here goes.
Lemma 1:Similar things tend to occur in similar contexts
Nice. Kinda obvious, intuitive and I added the “tend to” part to cover any hopefully rare contrary edge cases but as this is a statistical thing we are building, that’s OK. Also, I want to start slow with something that seems self-evident to us like “the shortest distance between two points is a straight line” from Euclidian Geometry.
Lemma 2:Facets are a tool for exploring meta-informational contexts
OK, that is what we have just gone through space and time warp explanations to get to, so lets put that in as our second axiom.
In laying out a Theorem we now go to the “it therefore follows that”:
Theorem:Facets can be used to find similar things.
Bingo, we have our Theorem and we already have some data points – we used Paul McCartney’s meta-informational context to find John Lennon, and we used facets to find related keywords that are all related to the same subject area (part 2 document clustering blog is coming soon, promise). So it seems to be workable. We may not have a “proof” yet, but we can use this initial evidence to keep digging for one. So lets keep looking for more examples and in particular for examples that don’t seem to fit this model. I will if you will.
Getting to The Why
So this seems to be a good explanation for why the all of the crazy but disparate seeming stuff that I have been doing with facets works. To me, that’s pretty significant, because we all know that when you can explain “why” something is happening in your code, you’ve essentially got it nailed down, conceptually speaking. It also gets us to a point where we can start to see other use cases that will further test the Facet Theorem (remember, a Theorem is not a Proof – but its how you need to start to get to one). When I think of some more of them, I’ll let you know. Or maybe some optimizations to my iterative, hard to parallalize method.
Facets and UI – Navigation and Visualization
Returning to the synonyms search vendors used for facets – Fast ESP first called these things ‘Navigators’ which Microsoft cleverly renamed to ‘Refiners’. That makes perfect sense for my synthesis – you navigate through some space to get to your goal, or you refine that subspace which represents your search goal – in this case, a set of results. Clean, elegant, it works, I’ll take it. The “goal” though is your final metadata set which may represent some weird docs if your precision sucks – so the space is broken up like a bunch of isolated bubbles. Mathematicians have a word for this – disjointed space. We call it sucky precision. I’ll try to keep these overly technical terms to a minimum from now on, sorry.
As to building way cool interactive dashboards, that is facet magic as well, where you can have lots of cool eye candy in the form of pie charts, bar charts, time-series histograms, scatter plots, tag clouds and the super way cool facet heat maps. One of the very clear advantages of Solr here is that all facet values are computed at query time and are computed wicked fast. Not only that, you can facet on anything, even stuff you didn’t think of when you designed your collection schema through the magic of facet and function queries and ValueSource extensions. Endeca could do some of this too, but Solr is much better suited for this type of wizardry. This is “surfin’ the meta-informational universe” that is your Solr collection. “Universe” is apt here because you can put literally trillions of docs in Solr and it also looks like the committers are realizing Trey’ Grainger’s vision of autoscaling Solr to this order of magnitude, thus saving many intrepid DevOps guys and gals their nights and weekends! (Great talk as usual by our own Shalin Mangar on this one. Definitely a must-see on the Memorex versions of our talks if you didn’t see his excellent presentation live.) Surfin’ the Solr meta-verse rocks baby!
Facets? Facets? We don’t need no stinkin’ Facets!
To round out my discussion of what my good friend the Search Curmudgeon calls the “Vengines” and their terms for facets, I ended that slide with an obvious reference to everyone’s favorite tag line from the John Huston/Humphrey Bogart classic The Treasure of the Sierra Madre, with the original subject noun replaced with “Facet”. As we all should know by now, Google uses Larry’s page ranking algorithm also known as Larry Page’s ranking algorithm – to whit PageRank, which is a crowd sourcing algorithm that works very well with hyper linked web pages but is totally useless for anything else. Google’s web search relevance ranking is so good (and continues to improve) that most of the time you just work from the first page so you don’t need no stinkin’ facets to drill in – you are most often already there and what’s the difference between one or two page clicks vs one or two navigator clicks?
I threw in Autonomy here because they also touted their relevance as being auto-magical (that’s why their name starts with ‘Auto’) and to be fair, it definitely is the best feature of that search engine (the configuration layer is tragic). This marketing was especially true before Autonomy acquired Verity, who did have facets, after which is was much more muddled/wishy washy. One of the first things they did was to create the Fake News that was Verity K2 V7 in which they announced that the APIs would be “pin-for-pin compatible” to K2 V6 but that the core engine would now be IDOL. I now suspect that this hoax was never really possible anyway (nobody could get it to work) because IDOL could not support navigation, aka facet requests – ’cause it didn’t have them anywhere in the index!! Maybe if they had had Yonik … And speaking of relevance, like the now historical Google Search Appliance “Toaster“, relevance that is autonomous as well as locked down within an intellectual property protection safe is hard to tune/customize. Given that what is relevant is highly contextual – this makes closed systems such as Autonomy and GSA unattractive compared to Solr/Lucene.
But it is interesting that the two engines that consider relevance to be their best feature, eschew facets as unnecessary – and they certainly have a point – facets should not be used as a band-aid for poor relevance in my opinion. If you need facets to find what you are looking for, why search in the first place? Just browse. Yes Virginia, user queries are often vague to begin with and faceted navigation provides an excellent way to refine the search, but sacrificing too much precision for recall will lead to unhappy users. This is especially true for mobile apps where screen real estate issues preclude extensive use of facets. Just show me what I want to see, please! So sometimes we don’t want no stinkin’ facets but when we do, they can be awesome.
Finale – reprise of The Theorem
So I want to leave you with the take home message of this rambling, yet hopefully enlightening blog post, by repeating the Facet Theorem I derived here: Facets can be used to find similar things. And the similarity “glue” is one of any good search geek’s favorite words: context. One obvious example that we have always known before, just as Dorothy instinctively knew how to get home from Oz, is in faceted navigation itself – all of the documents that are arrived at by facet queries must share the metadata values that we clicked on – so they must therefore have overlapping meta-informational contexts along our facet click’s navigational axes! The more facet clicks we make, the “space” of remaining document context becomes smaller and their similarity greater! We can now add this to our set of use cases that support the Theorem, along with the new ones I have begun to explore such as text mining, dynamic typeahead boosting and typeahead security trimming. Along these lines, a dashboard is just a way cooler visualization of this meta-informational context for the current query + facet query(ies) within the global collection meta-verse, with charts and histograms for numeric and date range data and tag clouds for text.
So to conclude, facets are fascinating, don’t you agree? And the possibilities for their use go well beyond navigation and visualization. Now to get the document clustering blog out there – darn day job!!!
During indexing, whenever a document is deleted or updated, it’s not really removed from the index immediately, it’s just “marked as deleted” in its original segment. It doesn’t show in search results (or the new version is found in the case of update). This leads to some percentage of “waste”; your index may consist of, say, 15%-20% deleted documents.
In some situations, the amount of wasted space is closer to 50%. And there are certain situations where the percentage deleted documents can be even higher, as determined by the ratio of numDocs to maxDocs in Solr’s admin UI.
Having half or more of your index “wasted” isn’t ideal, this article explains how these conditions arise and what to do about it (spoiler: not a lot).
NOTE: We talk about “deleted” documents. For the purposes of this article, “deleted” includes both explicit deletes and updates to existing documents. This latter is implemented as a delete of the original document followed by an add.
Good news, bad news
The good news is it’s easy to avoid having more than 50% of your index consist of deleted documents; do not optimize. We’ll talk about what it is about optimize (aka forceMerge) that can allow more than 50% of the index to consist of deleted documents later.
The bad news is there’s no configuration setting as of Solr 7.0.1 that will guarantee that no more than 50% of your index consists of deleted documents. This topic is under active discussion on the Apache JIRA list at LUCENE-7976.
Lucene segments are “write once”:
Since about forever, Lucene indexes have been composed of “segments”. A single segment consists of multiple files sharing the same root name but different extensions. A single segment consists of files like _0.fdt, _0.fdx, _0.tim and the like.
Lucene has a “write once” policy with respect to segments. Whenever a “hard commit” happens, the current segment is closed and a new one opened. That segment is never written to again [1]. So say a segment contains 10,000 documents. Once that segment is closed, that segment will always contain 10,000 documents, even if some are marked as deleted.
This can’t go on forever, you’d run out of file handles if nothing else.
Merging to the rescue:
The solution is “merging”. We mentioned above that when a commit happens, the segment is closed. At that point Lucene examines the index for segments that can be merged. There are several “merge policies”, all of them decide that some segments can be combined into a new segment and the old segments that have been merged can be removed. The critical point is that when segments are merged, the result does not contain the deleted documents.
Say two segments, each consisting of 10,000 docs 2,500 of which are deleted. These two segments are combined into a single new segment consisting of 15,000 documents, the 2,500 deleted documents from each original segment are purged during merge.
Anyway so far so good. And the default TieredMergePolicy (TMP) usually keeps the number of deleted documents in an index around 10-15%.
It turns out, though, that there are situations where the various merge policies result in some behaviors that can result in up to 50% deleted documents in an index.
Why is merging done like this?
It’s always a balancing act when creating merge policies. Some options are:
Merge any segments with deleted documents. I/O would go through the roof and indexing (and querying while merging) performance would plummet. In the worst case scenario you would rewrite your entire index after deleting 0.01% of your documents.
Reclaim the data from the segments when documents were deleted. Unfortunately that would be equivalent to rewriting the entire index. These are very complex structures and just reaching in and deleting the information associated with one doc is prohibitively expensive.
What? I can’t afford 50% “wasted” space:
Indeed. So how does that happen in the first place? Well, it gets a little tricky. Note that there is a “max segment size” that defaults to 5G that I’m using here, which can be configured higher or lower.
The root problem is that only segments with < 50% “max segment size” live documents are eligible for merging.
Let’s take an idealized 200G index consisting of exactly 40 segments each 5G in size. Further assume that docs in the corpus are updated randomly. None of these segments are eligible for merging until they contain < 2.5G “live” documents. Eventually all of the original 40 segments will have 2.51G “live” documents (or close enough to 50% for me).
You can see Michael McCandless’ writeup here, with graphs! He’s been deeply involved in the merging code.
What can I do about this?
Unfortunately, not much. Here are some ideas people have had:
forceMerge (aka optimize) or expungeDeletes. These operations will, indeed, remove all deleted documents if you forceMerge and merge all segments over a certain percent in expungeDeletes. However, the downside here is that once you optimize, you have to keep optimizing it or live with lots of deleted documents [2]. The reason for this is that forceMerge (and expungeDeletes for that matter) create a large segment as a result [3]. In a 100G index example that single segment will be 100G despite the (default) 5G max segment size. Now to become eligible for merging, that single large segment must have < 2.5G “live” documents, it’ll have up to 97.5% wasted space.
Make the max segment size bigger. We mentioned that this defaults to 5G, which can be done through a setting in solrconfig.xml. Changing the max segment size makes no difference since the problem isn’t how big each segment can be, it’s the fact that the segment is not considered for merging until is has < 50% of max segment size undeleted documents.
Dig into the arcana of the merge policy and tweak some of the lower-level parameters. There are properties like “reclaimDeletesWeight” that can be configured by tweaking TieredMergePolicy in solrconfig.xml. None of those parameters matter since they don’t come into play until the segment has < 50%(max segment size) live documents, and there’s no option to configure this.
So where exactly does that leave us?
Lucene indexing has served well for years, so this is an edge case. Unless you are running into resource problems, it’s best to leave merging alone. If you do need to address this there are limited options at present:
Optimize/forceMerge/expungeDeletes. These options will remove some or all of the deleted documents from your index. However, as outlined above, these operations will create segments much larger than the maximum considered for future merges and you’ll have to perform these operations routinely. OPTIMIZING IS NOT RECOMMENDED FOR NRT INDEXES! These are very heavy-weight operations, generally suitable only for very slowly changing indexes.
Cleverly execute optimize/forceMerge. You can optionally tell the optimize/forceMerge operation to merge into N segments instead of just a single one, where N is something like (fudge factor) + (total index size)/(max segment size). Theoretically, that would not run into the pathological situation where > 50% of your index consisted of deleted documents. This is not explicitly supported behavior so I’d be very reluctant to predict the behavior.
Change the code. Either create a patch for LUCENE-7976 or propose a new merge policy.
Conclusion:
This article looks scary, but do remember that TieredMergePolicy has been around for a long time and has served admirably. We created this document to provide a reference for those situations where users notice that their index consists of a greater percentage of deleted documents than expected. As Solr and Lucene move into ever-larger document sets, it may be time to tweak TieredMergePolicy and/or create a new merge policy and that discussion is already under way.
[1] We’re simplifying a little here, the documents in that segment are marked as deleted in a separate file associated with that segment, so in that sense the segment is written to after it’s closed. But that’s unimportant for this discussion.
[2] We’re simplifying again here. If your index is unchanging, or if you always add new documents so no documents are ever updated or deleted, optimizing doesn’t have this downside since there won’t be deleted documents in your index and will show some improved response time.
[3] You can specify that the result of forceMerge will be more than one segment, but that doesn’t change the overall situation.
I’m not saying that your search platform is bad if it doesn’t fully address these issues… I’m saying it is horrifying! I’m saying you should dress it up on Halloween and put it in your yard to scare children away (so you can eat all the candy yourself)!
Here are 7 ghoulish limitations that no search app should tolerate:
Security Not Enabled
Years ago, I worked for a company with poorly tuned, insecure intranet search. At that company, I found files showing a plan which involved laying off the entire department I was in – months before it was intended to go into effect. I was the last guy who really knew Oracle and the company really needed me there until it could phase out our department. However, there was nothing in the plan about a long and generous severance and I had rent to pay, so I found a new job months in advance.
Security integration and security trimming allow you to ensure that users do not see documents in search results they don’t have permission to access. This also applies to content repositories like SharePoint, Box, or Google Drive. You configure this at index time to capture permissions from the repository and supply a username parameter at query time in order to filter the search results.
No Idea What Terms to Start With
When I see a blank search box and type the letter “A” and nothing comes up, it is rather jarring. In the early days of search, this was expected behavior. Even Google worked that way. However with auto-complete on a smartphone or auto-suggest on Google and Amazon, everyone expects some kind of direction as they start typing in the search box.
Suggestions and typeahead supply keywords to users as they type their query. This feature is frequently combined with category suggestions (facets) to help tune search to exactly what the user is looking for. There is no reason to fly blind.
No Categorization
In a modern Fortune 1000 company there is no shortage of data. It is insights that matter. Data consolidation and being able to search across data sources is absolutely essential to answering the kinds of hard business questions teams must answer every day. However, a keyword search that isn’t tuned to any particular area or domain will tend to return noise.
Faceting allows users to limit their search to some subdivision of data that is related to them. If you have a field in your data that lends itself to that naturally then this is easy to do. However, if you don’t then tools like classifiers and clustering are essential. These can either assist a human at categorizing data (supervised learning) or just find which data is related to which without a human getting involved (unsupervised learning).
No Measure of Success
There are plenty of companies that deploy search and don’t actually measure or have no way to measure if users are successfully finding… well… anything. Unless users complain, IT just assumes everything is fine. Meanwhile the users that aren’t complaining abandoned the company’s search long ago and either use a series of emailed bookmarks or Google for public sites.
Any idiot can put out a search app that shows some of the data. Years ago I put a simple (now defunct) free software tool called htDig in front of a bunch of Word documents. I read them by running the unix “strings” commands against them. It was a simple enough keyword search for a very small corpus so long as you weren’t looking for something too specific and it did nothing for some of the more complicated documents because it couldn’t REALLY see inside them. Oddly this was part of a motivation for creating a project that eventually became Apache POI. POI (via Apache Tika) eventually became the way Fusion read Office documents. htDig sorta worked but it couldn’t “really” look into my Word documents let alone any other file types.
If your search tool can’t “really” see all the way inside your documents it can’t really index them properly. It took years to develop the tools that could really do this. A good search solution is extensible – there is always a new file format or data source – and ideally uses well thought out, proven open source technologies.
Nothing Personal(alized)
Back in the day you had to learn to construct a search for Google. Now Google kinda knows enough about your past behavior, social networks, and geography to predict what you’re actually looking for. This personalization of search is no longer a luxury but essential to satisfy modern users.
Your search solution needs to track signals like clickstreams and which queries the user entered in the past. Your search solution should allow you to inform future queries with actual purchases or how long a user stayed on a page.
Like No Other
The “more like this” feature on Google isn’t all that useful. It usually obscures results Google hid from you because they were mostly repetitive. That’s an area Google got wrong. It is frequently helpful to find something and explore its kin in order to find just the thing you want. In retail this looks like similar items (another shoe in a different style). In enterprise search these are similar documents (maybe a form from a different year or tax type or similar blueprint).
A good search solution lets you find “more like this” based on keywords but also allows you to automatically cluster or classify like items. Users should be able to navigate their way to their perfect result. They shouldn’t have to get there the first time.
The Tricks That Make Fusion a Treat
Fusion is built on Apache Solr, Apache Tika, Apache Spark and a whole lot of other open source tools that have been in the works for decades. A lot of R&D and thought went into them and made them into a complete information management solution for finding your stuff! Lucidworks wove these separate pieces into a total solution and added more functionality like machine learning that mere mortals can implement and an Index Workbench that allows you to tune your data ingestion and see the results in real-time.
“I hate people who don’t know the difference between “your” and “you’re”. There so stupid!!”
You’ve probably gotten tired of me by now, that’s OK because I’m tired of me too. Believe me, you don’t have to live with me – I do. You may be thinking – “Who’s this Search Curmudgeon guy? He’s a real jerk”. No argument there. But if you have gotten this far into the blog – that is, you got past the author tag line “By Search Curmudgeon” without clicking off (which at this point might make a tweet with some texting-style lingo like ‘lol’ and lots of emojis) maybe I am being too self-critical.
I make my living working with computers but that doesn’t mean that I’m in love with the damn things. I mean, it scares the heck out of me that my car is essentially a computer now. “Raid kills Bugs Dead” could now become “Bugs kill People Dead”. The more you know about computers, the more you will agree with that! It reminds me of an old internet joke that was at least mildly amusing at the time because it was really about computer programmer geeks like myself, not computers – and it was ludicrous. It may still be funny now – you be the judge – but now its also true. The joke went something like this. Three engineers are driving in a car, an electrical engineer, a mechanical engineer and a software engineer. The car breaks down and they get into an argument about what’s wrong with it. The electrical engineer says “It must be the ignition system”, the mechanical engineer says “No, its gotta be the transmission” and the software engineer says – “Well, why don’t we just get out of the car and then get back in?” I’ll wait till the laughter subsides …
In any case, fast forwarding to the now, I was driving my new car and somehow the blind-spot warning system went offline (a really cool innovation by the way!). I was left to fend off potential lane incidents the old fashioned way – I had to actually LOOK behind me before making a lane change!!! OMG!! I was pretty stressed out – I mean, its a brand new car and now I have to take it back to the dealer to find out why the blind-spot warning system only lasted a few thousand miles. Then it hit me – its software dummy, – maybe I didn’t give it a chance to load when I tried to call my girlfriend using the voice-activated bluetooth (another awesome thing) before the voice recognition system had a chance to initialize itself … So, sure enough when I restarted the car the next morning, the system came up, good as new like nothing had happened. (The Curmudgeon has a girlfriend?? Yes, I do. <G>) A software failure in the blind spot warning system I can live with, but what else can go wrong? Unfortunately, lots of things. Now when you take your car back to the dealer for a recall, more often than not they will be installing a new software patch – or maybe they could spare you the trip and do what Microsoft does with your home PC, update and reboot your car computer’s OS remotely at the least convenient moment, i.e. while you are driving. … No, they’re (or should it be ‘their’ ?) not that stupid … are they? “I’m sorry officer, it wasn’t my fault. Just as I was pulling onto the Interstate, Microsoft rebooted my car.”
But enough about cars, I’m here to talk about (ah rant that is) search related stuff. But the theme is established – we have grown so enamored of what computers can do for us that we let them do as many things as we can think of – especially really cool things. But lets take a step back for a moment. Bugs aside (like the poor, they will always be with us), are computers capable of doing everything that we want them to (yet)? I stress the word “want” here, because you really can’t always get what you want – thanks Mick and Keith – because what we should be focusing on is getting what we need them to do. We should do this when doing it ourselves is A) too tedious or overwhelming (or we are just lazy) and 2) we know that the computer can do it really well and really fast. So we need a case clause in our project management software labeled – “Yes – computers are really good at that.” and “No – computers totally suck at that”, and let humans pick up the slack. Pushing the envelope technologically speaking is important, but we need to be sensible too. And hiring people back is better for the economy.
As another example of what I am talking about, have you ever overheard someone talking into their cell phone where the “person” they are talking to is obviously not one? It often goes something like this:
“yes …. yes …. yes …. repeat menu …. yes …. no …. yes …. yes …. I don’t know …uhhh … SH*T … Can I please talk to a person now? … oh OK REPRESENTATIVE!!”
And since programmers usually have a good sense of humor (they have to or they would go insane) and can detect expletives in the output of the voice recognition system, the computer unbeknownst to you – or maybe beknownst if quite obnoxiously they had it on speaker – might have responded:
“I don’t respond to profanity – please say ‘I’m Sorry’ and then select a menu option – and if you do it again, I’m going to call your Mom.”
But wouldn’t it be cool if we had one of these for ourselves to screen our calls like businesses do? We could have our app say “Please respond to one of the following menu options: 1 – Family, 2 – Friend, 3 – Business Associate, 4 – Doctor’s Office, 5 – Bill Collector, 6 – Solicitor/Telemarketer/”Courtesy Caller”, 7 – Computer”. If the answer is 1, 2 or 3 we could provide some security questions like “What did I do to the dog when I was 3?” (if family). or “What’s my favorite drinking spot?” (if friend) or “What’s my typical Starbucks order?” (business associate). For 4 we would have it ask “What’s my Date of Birth?”. For 5 and 6, we can have our app just say “F*ck Off” and “Not Interested” respectively and hang up. I’m not sure what to do if our app is called by another computer. In the worst case scenario, this could cause an infinite recursion that would drive our cell phone bill through the roof. (“Sorry Verizon, your robo-caller and my personal answering app were stuck in an infinite loop 47 times last month – no, I not going to pay the $15,632.27 – just shut the damn thing off – I’m switching to T-Mobile.”)
So these computer phone answering systems are now ubiquitous. Quick quiz – when was the last time that you spoke to a person on the initial call to a bank, insurance company or, ah snap, basically any business? That is because we have fired most of the phone support workers and replaced them with that same robotic female voice that our GPS and car bluetooth systems use. Likewise, in the search business, we’ve fired the librarians and replace them with HP Autonomy IDOL (now commonly referred to as Autonomy IDLE thanks to me – heh heh). It used to be back in the day that these people would be hired to help other employees find information. They were experts at getting information out of systems that had inscrutable UI’s and complex arcane query languages (uh to be more precise – query programming languages). Then Google came along and everything changed. Ah, we don’t need these people anymore, we can just have our employees “Google It”. This works as far as it goes, but in the enterprise, it doesn’t go very far.
But I am NOT saying that search systems are still so bad that they can only be used effectively by someone with a Masters in Library Science degree or an MLS – which also stands for “More Literate Sh*t”, to put it in the pantheon of degree acronym joke rewordings that began with “BullSh*t”, “Bullsh*t Artist”, “Master Bullsh*t Artist”, “More Sh*t” and “Piled Higher and Deeper” (yours truly). Far from it. We have come a long way in that respect as our apps have become Goggle-ized and the arcane “Advanced Search” screen is largely a thing of the past. What I am saying is that the systems can get even better if we hire some of the librarians back (definitely Marian but not Conan The Librarian to be sure) to help us make them smarter – because in my opinion (notice that I didn’t say ‘humble’ because that is one thing that the Curmudgeon is definitely NOT) – there are still some things that computers suck at in the search world and won’t be totally solved by armies of software developers any time soon. Maybe they eventually will, but in the meantime there is still work for humans. And that work is to help the computer understand semantic contexts by engaging them with lexical knowledge bases. I’m a humanist believe it or not – I like humans even if they don’t like me sometimes – I EARNED my nickname of ‘curmudgeon’ you know.
Now I know that “Taxonomy” is a dirty word to many especially the “Just let the Wookie – uh – machine do it.” crowd – who always say “But that’s too slow and it doesn’t scale, nyah, nyah, pants on fire” – as if scale and speed are everything. Their systems may provide crappy answers – but they provide them really fast and can do it at tremendous scale. Now we don’t have to find a gas station to ask for directions and end up speaking to an attendant who doesn’t speak much English – we can talk to our car computer’s GPS which understands English about as well. This may or may not be more enlightening when you are lost but it is undoubtedly a much faster way to get unhelpful information.
What I am really getting at here is that for every 5 or 6 software developers that you hire, hire one person who’s job is to create or find data sets that the software developers can use to build smarter systems. There are a lot of really good open source knowledge bases out there – especially in healthcare – but it takes time and effort to 1) find them and C) integrate them to the current purpose. Taxonomies or ontologies, synonym lists, phrase lists, stopwords lists, precomputed Word2Vec models, DBPedia, Open Calais etc. etc. etc. But the time invested in doing this is well worth it. Your users will thank you for it, believe me. You don’t have to boil the ocean here. The more semantic knowledge the computer has to work with, the better it does at listening and talking to humans (even without emojis). So you can start small and build your vocabulary sets more enthusiastically as you see your search relevance start to zoom up or see your click-through rates start to become very respectable (and more to the point, profitable!).
For example. I don’t know how many times I’ve engaged with a customer who was unhappy with their Solr search engine’s relevance and find that their synonyms.txt file just knows that “Television” == TV and that “fooaaa”, “baraaa”, and “bazaaa” mean the same thing. If you don’t get this joke, look at the ‘synonyms.txt’ file that ships with Solr 6.2 – and by the way, what the hell is a “pixma”? OK, its a Canon printer model – thanks again Google!. Maybe the customer thinks that “it should just work” out of the box. Yeah, if the user types in “aaafoo” – the search engine will return stuff that has “aaabar” as well! Cool right? Works for me – no kidding, that’s how I unit test search code too – lots of documents named “Test Document 42” where “foo”, “bar”, “baz”, and “bat” are all keywords. And speaking of “foobar”, another anecdote that I inferred from watching “Saving Private Ryan” is that “foobar” is derived from the military FUBAR which stands for – oh you know – but I’ve used more than enough profanity for one blog post already so I’ll sanitize it – “F*cked Up Beyond All Recognition”. And if you read my last blog post, note that “foo” rhymes with “poo” – not sure what relevance that observation has though. Maybe the first programmer who used this to document something meant to say “fubar” but since programmers are notorious for being crappy spellers … And trust me, there is a lot of “foobar” (sic) code out there – I’ve seen more than my share. Maybe that’s why I’m such a curmudgeon.
No people, the OOTB ‘synonyms.txt’ file that ships with Solr is intended to document how to write one – i.e. what its syntax is. It is NOT intended to be used in production applications, but surprisingly it crops up there far too often. Why? Because we have fired all of the librarians who actually understand why we need to edit and maintain this thing. Machine learning algorithms can deal with two types of data – data to analyze and data to help the algorithm analyze other data. Yes, there is a major scaling problem with terms and phrases but there are already vocabularies out there like WordNet that are tackling this issue and some very cool entity extraction software to find phrases automagically. And scale is relative to the domain you are in. WordNet may not know about your business’ product names or specialized jargon for example (Google may because it crawled your website but this data may not be for sale). In as much time as it takes 14 developers to design, code, test, debug, test, debug, test, debug, test, re-design, re-code, test, debug, test, debug, test and deploy (phew!) a complex enterprise application, one or two librarians can create a fairly complete lexicon for the enterprise with the important phrases, stopwords and synonyms that can feed a kick-ass Lucene Analyzer chain or do some bitchin’ query expansions. The programmers don’t even have to lift a finger in this case because maybe some of them aren’t even aware of ‘synonyms.txt’ to begin with. Let them think that their magic code is what improved the search results.
Or even better have them integrate a “Taxonomy” which is a dirty word in some circles. Just have your Librarians refer to it as a “lexicon” or “vocabulary” and nobody will notice.
If the individual “Query” objects (q & zero or more fq parms) have caching enabled (it is by default)
… but further nuances come into play depending on:
The effective cost param specified on each fq (defaults to ‘0’ for most queries)
The type of the underlying Query object created for each fq: Do any implement the PostFilter API?
As I explained some of these nuances on IRC (and what they change about the behavior) I realized 2 things:
This would make a really great blog post!
I wish there was a way to demonstrate how all this happens, rather then just describe it.
That led me to wonder if it would be possible to create a “Tracing Wrapper Query Parser” people could use to get get log messages showing when exactly a given Query (or more specifically the “Scorer” for a that Query) was asked to evaluated each document. With something like this, people could experiment (on small datasets) with different q & fq params and different cache and cost local params and see how the execution changes. I made a brief attempt at building this kind of QParser wrapper, and quickly got bogged down in lots of headaches with how complex the general purpose Query, Weight, and Scorer APIs can be at the lower level.
On the other hand: the ValueSource (aka Function) API is much simpler, and easily facilitates composing functions around other functions. Solr also already makes it easy to use any ValueSource as a Query via the {!frange} QParser — which just so happens to also support the PostFilter API!
A few hours later, the “TraceValueSource” and trace() function syntax were born, and now I can use it to walk you through the various nuances of how Solr executes different Queries & Filters.
IMPORTANT NOTE:
In this article, we’re going to assume that the underlying logic Lucene uses to execute a simple Query is essentially: Loop over all docIds in the index (starting at 0) testing each one against the Query, if a document matches record it’s score and continue with the next docId in the index.
Likewise we’re going to assume that when Lucene is computing the Conjunction (X ^ Y) of two Queries, the logic is essentially:
Loop over all docIds in the index (starting at 0) testing each one against X until we find a matching document
if that document also matches Y then record it’s score and continue with the next docId
If the document does not match Y, swap X & Y, and start the process over with the next docId
These are both extreme over simplifications of how most queries are actually executed — many Term & Points based queries are much more optimized to “skip ahead” in the list of documents based on the term/points metadata — but it is a “close enough” approximation to what happens when all Queries are ValueSource based for our purposes today.
{!frange} Queries and the trace() Function
Let’s start with a really simple warm up to introduce you to the {!frange} QParser and the trace() function I added, beginning with some trivial sample data…
For most of this blog I’ll be executing queries against these 4 documents, while showing you:
The full request URL
Key url-decoded request params in the request for easier reading
All log messages written to solr.log as a result of the request
The {!frange} parser allows user to specify an arbitrary function (aka: ValueSource) that will be wrapped up into a query that will match documents if and only if the results of that function fall in a specified range. For example: With the 4 sample documents we’ve indexed above, the query below does not match document ‘A’ or ‘C’ because the sum of the foo_i + bar_i fields (42 + 100 = 142 and -7 + 1000 = 993 respectively) does not fall in between the lower & upper range limits of the query (0 <= sum(foo_i,bar_i) <= 100) …
Under the covers, the Scorer for the FunctionRangeQuery produced by this parser loops over each document in the index and asks the ValueSource if it “exists” for that document (ie: do the underlying fields exist) and if so then it asks for the computed value for that document.
Generally speaking, the trace() function we’re going to use, implements the ValueSource API in such a way that any time it’s asked for the “value” of a document, it delegates to another ValueSource, and logs a message about the input (document id) and the result — along with a configurable label.
If we change the function used in our previous query to be trace(simple_sum,sum(foo_i,bar_i)) and re-execute it, we can see the individual methods called on the “sum” ValueSource in this process (along with the internal id + uniqueKey of the document, and the “simple_sum” label we’ve chosen) and the result of the wrapped function …
Because we’re using the _default Solr configs, this query has now been cached in the queryResultCache. If we re-execute it no new “tracing” information will be logged, because Solr doesn’t need to evaluate the ValueSource against each of the documents in the index in order to respond to the request…
There’s a lot of information here to consider, so let’s break it down and discuss in the order of the log messages…
In order to cache the individual fq queries for maximum possible re-use, Solr executes each fq query independently against the entire index:
First the “pos_foo” function is run against all 4 documents to identify if 0 <= foo_i
this resulting DocSet is put into the filterCache for this fq
then the “low_bar” function is run against all 4 documents to see if bar_i <= 90
this resulting DocSet is put into the filterCache for this fq
Now the main query (simple_sum) is now ready to be run:
Instead of executing the main query against all documents in the index, it only needs to be run against the intersection of the DocSets from each of the individual (cached) filters
Since document ‘A’ did not match the “low_bar” fq, the “simple_sum” function is never asked to evaluated it as a possible match for the overall request
Likewise: since ‘B’ did not match the “pos_foo” fq, it is also never considered.
Likewise: since ‘C’ did not match the “low_bar” fq, it is also never considered.
Only document “D” matched both fq filters, so it is checked against the main query — and it is a match, so we have hits=1
In future requests, even if the main q param changes and may potentially match a different set of values/documents, the cached filter queries can still be re-used to limit the set of documents the main query has to check — as we can see in this next request using the same fq params…
Let’s again step through this in sequence and talk about what’s happening at each point:
Because the filters are not cached, Solr can combine them with the main q query and execute all three in one pass over the index
The filters are sorted according to their cost, and the lowest cost filter (low_bar_nocache_25) is asked to find the “first” document it matches:
Document “A” is a match for low_bar_nocache_25 (bar_i <= 100) so then the next filter is consulted…
Document “A” is also a match for pos_foo_nocache_50 (0 <= foo_i) so all filters match — the main query can be consulted…
Document “A” is not a match for the main query (simple_sum)
The filters are then asked to find their “next” match after “A”, beginning with the lowest cost filter: low_bar_nocache_25
Document “B” is a match for ‘low_bar_nocache_25’, so the next filter is consulted…
Document “B” is not a match for the ‘pos_foo_nocache_50’ filter, so that filter keeps checking until it finds it’s “next” match (after “B”)
Document “C” is not a match for the ‘pos_foo_nocache_50’ filter, so that filter keeps checking until it finds it’s “next” match (after “C”)
Document “D” is the “next” match for the ‘pos_foo_nocache_50’ filter, so the remaining filter(s) are consulted regarding that document…
Document “D” is also a match for the ‘low_bar_nocache_25’ filter, so all filters match — the main query can be consulted again.
Document “D” is a match for the main query (simple_sum), and we have our first (and only) hit for the request
There are two very important things to note here that may not be immediately obvious:
Just because the individual fq params indicate cache=false does not mean that nothing about their results will be cached. The results of the main q in conjunction with the (non-cached) filters can still wind up in the queryResultCache, as you can see if the exact same query is re-executed…
…we don’t get any trace() messages, because the entire “q + fqs + sort + pagination” combination was in the queryResultCache.
(NOTE: Just as using cache=false in the local params of the fq params prevent them from being put in the filterCache, specifying cache=false on the q param can also prevent an entry for this query being added to the queryResultCache if desired)
The relative cost value of each filter does not dictate the order that they are evaluated against every document.
In the example above, the higher cost=50 specified on on the ‘pos_foo_nocache_50’ filter did not ensure it would be executed against fewer documents then the lower cost ‘low_bar_nocache_25’ filter
Document “C” was checked against (and ruled out by) the (higher cost) ‘pos_foo_nocache_50’ filter with out ever checking that document against the lower cost ‘low_bar_nocache_25’
The cost only indicates in what order each filter should be consulted to find it’s “next” matching document after each previously found match against the entire request
Relative cost values ensure that a higher cost filter will not be asked to find check the “next” match against any document that a lower cost filter has already definitively ruled out as a non-match.
Compare the results above with the following example, where the same functions use new ‘cost’ values:
The overall flow is fairly similar to the last example:
Because the filters are not cached, Solr can combine them with the main query and execute all three in one pass over the index
The filters are sorted according to their cost, and the lowest cost filter (pos_foo_nocache_10) is asked to find the “first” document it matches:
Document “A” is a match for pos_foo_nocache_10 (0 <= foo) — so the next filter is consulted…
Document “A” is a match for low_bar_nocache_80 (bar <= 100) — so all filters match, and so the main query can be consulted…
Document “A” is not a match for the main query (simple_sum)
The filters are then asked to find their “next” match after “A”, beginning with the lowest cost filter: (pos_foo_nocache_10)
Document “B” is not a match for the ‘pos_foo_nocache_10’ filter, so that filter keeps checking until it finds it’s “next” match (after “B”)
Document “C” is not a match for the ‘pos_foo_nocache_10’ filter, so that filter keeps checking until it finds it’s “next” match (after “C”)
Document “D” is the “next” match for the ‘pos_foo_nocache_10’ filter, so the remaining filter(s) are consulted regarding that document…
Document “D” is also a match for the ‘low_bar_nocache_80’ filter, so all filters match — the main query can be consulted again.
Document “D” is a match for the main query, and we have our first (and only) hit for the request
The key thing to note in these examples, is that even though we’ve given Solr a “hint” at the relative cost of these filters, the underlying Scoring APIs in Lucene depend on being able to ask each Query to find the “next match after doc#X”. Once a “low cost” filter has been asked to do this, the document it identifies will be used as the input when asking a “higher cost” filter to find it’s “next match”, and if the higher cost filter matches very few documents, it may have to “scan over” more total documents in the segment then the lower cost filter.
Post Filtering
There are a small handful of Queries available in Solr (notably {!frange} and {!collapse}) which — in addition to supporting the normal Lucene iterative scoring APIs — also implement a special “PostFilter” API.
When a Solr request includes a filter that is cache=false and has a cost >= 100 Solr will check if the underlying Query implementation supports the PostFilter API; If it does, Solr will automatically use this API, ensuring that these post filters will only be consulted about a potential matching document after:
It has already been confirmed to be a match for all regular (non-post) fq filters
It has already been confirmed to be a match for the main q Query
It has already been confirmed to be a match for any lower cost post-filters
(This overall user experience (and special treatment of cost >= 100, rather then any sort of special postFilter=true syntax) is focused on letting users indicate how “expensive” they expect the various filters to be, while letting Solr worry about the best way to handle those various expensive filters depending on how they are implemented internally with out the user being required to know in advance “Does this query support post filtering?”)
For Advanced Solr users who want to write custom filtering plugins (particularly security related filtering that may need to consult external data sources or enforce complex rules) the PostFilter API can be a great way to ensure that expensive operations are only executed if absolutely necessary.
Let’s reconsider our earlier example of non-cached filter queries, but this time we’ll use cost=200 on the bar < 100 filter condition so it will be used as a post filter…
Here we see a much different execution flow from the previous examples:
The lone non-cached (non-post) filter (pos_foo_nocache_50) is initially consulted to find the “first” document it matches
Document “A” is a match for pos_foo_nocache_50 (0 <= foo) — so all “regular” filters match, and the main query can be consulted…
Document “A” is not a match for the main query (simple_sum) so we stop considering “A”
The post-filter (low_bar_postfq_200) is never consulted regarding “A”
The lone non-post filter is again asked to find it’s “next” match after “A”
Document “B” is not a match for the ‘pos_foo_nocache_50’ filter, so that filter keeps checking until it finds it’s “next” match (after “B”)
Document “C” is not a match for the ‘pos_foo_nocache_50’ filter, so that filter keeps checking until it finds it’s “next” match (after “C”)
Document “D” is the “next” match for the ‘pos_foo_nocache_50’ filter — since there are no other “regular” filters, the main query is consulted again
Document “D” is also a match for the main query
After all other conditions have been satisfied Document “D” is then checked against the post filter (low_bar_postfq_200) — since it matches we have our first (and only) hit for the request
In these examples, the functions we’ve used in our filters have been relatively simple, but if you wanted to filter on multiple complex math functions over many fields, you can see how specifying a “cost” relative to the complexity of the function could be advantageous to ensure that the “simpler” functions are checked first.
In Conclusion…
Hopefully these examples I’ve walked through are helpful for folks trying to wrap their heads around how/why filter queries behave in various sitautions, and specifically how {!frange} queries work so you can consider some of the trade offs of tweaking the cache and cost params of your various filters.
Even for me, with ~12 years of Solr experience, running through these examples made me realize I had a missconception about how/when FunctionRangeQuery could be optimized (ultimately leading to SOLR-11641 which should make {!frange cache=false ...} much faster by default in future Solr versions)
If you visualize this as a document database (such as Apache Solr the back end to Lucidworks Fusion), there are a set number of fields associated with pilots and a set number of fields associated with flights. FAA regulations, pilot union work rules, and business rules set the conditions that make up the queries we’ll pass to Fusion and hence Solr.
Pilots have shift times, locations and vacation times. Flights have takeoff locations, takeoff times, landing locations and landing times.
In Fusion you model these locations as Solr spatial types like SpatialRecursivePrefixTreeFieldType and even simple LatLonPointSpatialField. These store essentially the X,Y coordinates of the plane, plane or anything you like. Solr can also model polygons and other “shapes” in space.
For the dates and times you have the DateRangeField. With it you can do a contains, within, or intersects operation.
Understanding the Rules
FAA regulations stipulate among other things that pilots:
Have 10h of downtime every 24h
Fly no more than 9h
Not be on vacation
Pilots are in a city, have to take a flight to a city either as a pilot or passenger.
American Airlines business rules say essentially:
A certain amount of vacation time is available based on excess pilot capacity
Pilots get priority for that vacation time based on seniority
Available vacation time as a schema might look like this:
ID – IntPointField
Date – DateRangeField
Number_allowed – IntPointField
It might be done as blocks or individual dates
Pilots “bids” on vacation time might be modeled like this:
ID – IntPointField – IntPointField
Time_period – IntPointField
Pilot – IntPointField
Implementing the Rules
Implementing this is really a set of searches and adding documents to collections. When looking for a pilot, a Fusion query pipeline can be set up which takes the flight as an argument but constructs a Solr query which is essentially a search for the closest pilot who hasn’t had 9 hours of shift. If no pilot is found in range, then a wider range query is executed that finds a pilot that can be flown there (which also involves a subquery on an available flight).
For the distance queries it looks like this in Solr’s query language: &q=:&fq={!bbox sfield=store}&pt=45.15,-93.85&d=1. Essentially if you start at 45.15,-93.85 lat,long and we assume there is an airport there, then within a box including +1 and -1 (i.e. 44.15 to 46.16 and -94.85 to -92.85). Through this we can find out if a pilot is “close” enough.
For the time ranges, the Solr query looks something like datefield:[2017-12-20T17:30:00.772Z TO 2017-12-20T18:30:00.772Z].
You can also compare two date ranges using an Intersects, Contains or Within query. In Solr a query looks like this: {!field f=Duration op=Contains}[2016-02-02T14:50 TO 2016-02-02T15:00].
For pilot vacation bids you have an orderby on hire date, that’s really it.
American: Call Me Maybe?
Clearly the rules are more complicated than what’s in the press. With that said, these are the basic sorts of problems they need to solve and Solr is super fast and well suited for that. Moreover Solr is proven, scalable, and has both high availability and disaster recovery taken care of.
When you add Fusion on top of Solr you can abstract away some of the complexity of this and even take advantage of AI to solve more advanced problems. So if you’re stuck in line this Christmas, think of this blog and think “Damn I wish they’d just use Fusion, then I wouldn’t be stuck in this line!” If you’re anyone else think about what problems you have that might be search problems and how you could use scalable, reliable and proven technology to solve them!
Here at Lucidworks we recently had an “exciting” adventure. A client wanted to access Streaming Expression functionality through SolrJ. This turned out to be more challenging than we expected so we thought it would be useful to create a blog post with our findings/recommendations.
Recommendation
Save yourself time and effort, and use the pattern described below. Do not try to assemble the low-level components yourself, unless you want to spend several days duplicating work done by the authors of the Streaming Expression code.
Yes, I know. Real Programmers assemble low-level code themselves because they’re, well, Real Programmers. The traditional rationale for using low-level constructs is it’s more efficient. Writing to a higher level means the only “inefficiency” here is that Solr will have to parse the expression. I maintain the time spent parsing the string version of a Streaming Expression is so minuscule compared to the work done by the query, that the “efficiency” of using low-level construct is completely lost in the noise. Really, spending several days (or weeks considering upgrading may require you to revisit your code) to gain 0.000000001% of the execution time will not make your boss happy.
Trust me on this.
Additionally, there is quite a bit of thought behind the process balancing incoming requests across your cluster. Higher-level constructs take care of this critical requirement for you, and do so with with considerable efficiency.
The analogy I often use is that you use Solr rather than Lucene to take advantage of all the work the Solr folks have done. Sure, it’s possible to bypass Solr completely, but a number of very intelligent people have worked very hard to allow you to solve your problem from a higher level, faster, and with less work. If you really, really, really need to work at a lower level it’s available. If I were your manager in this case, I would ask you to show why it’s worth the engineering time commitment before approving the effort.
Feel free if you insist, but consider this fair warning that trying to do so is:
A good way to go mad.
A good way to have to maintain code that you do not need to maintain.
A good way to miss the next sprint milestone.
Let’s take these one at a time
A good way to go mad
The Solr Streaming Expression implementation is complex. It enables powerful, albeit complex, functionality. There are maybe a dozen people on the planet who understand it all in detail.
Chances are, if you’re reading this blog for hints, you aren’t one of them.
A good way to have to maintain code…
The streaming functionality from the basic ‘/export’ handler through Streaming Expressions and ParallelSQL is evolving extremely quickly. Trying to work with the low-level code means that if the low-level code changes at all, you’ll have to revisit your code. This is not a valuable use of your time.
A good way to miss the next sprint deadline
Actually I’d say that it’s a good way to miss several sprint deadlines, you’ll see why in a bit.
Here’s the easy way
Let’s start with our recommended approach. Here’s a Streaming Expression (simplified, lots of details left out for clarity):
select(rollup(search search_parameters), rollup_parameters), select_parameters)
Say you’ve used the UI to build up to the expression and you’re satisfied with it. To construct the simple version, it looks like this:
String cexpr = "select(rollup(search search_parameters), rollup_parameters), select_parameters)";
ModifiableSolrParams paramsLoc = new ModifiableSolrParams();
paramsLoc.set("expr", cexpr);
paramsLoc.set("qt", "/stream");
// Note, the "/collection" below can be an alias.
String url = some_Solr_URL_in_your_cluster + "/collection" ;
TupleStream solrStream = new SolrStream(url, paramsLoc);
StreamContext context = new StreamContext();
solrStream.setStreamContext(context);
solrStream.open();
read_tuples_til_EOF;
solrStream.close(); // could be try-with-resources
The ‘cexpr’ above can be constructed any way you please, it’s just a string after all. Whatever works with curl or the expressions bit of the admin UI.
Here’s the hard way
Contrast the above with the code you’d have to write (and maintain!) if you tried to build up all this yourself (and I’m leaving out a great deal of code). By the way, after running into several problems we decided to make it easy on ourselves [1]. I’m using the same shorthand as above…
StreamExpression expression;
StreamContext streamContext = new StreamContext();
SolrClientCache solrClientCache = new SolrClientCache();
// What's this? Why do I need it? If I don't set it I'll get an NPE
streamContext.setSolrClientCache(solrClientCache);
// what if I can't get to the ZK host since I can't tunnel to it if I need to?
StreamFactory factory = new StreamFactory().
withCollectionZkHost(collection_name, ZK_ensemble_string);
// Wait, is /export right? Maybe it's /stream? Well, yes it should be /stream.
// But what if it changes in the future?
// well, the below works, but is it correct? Hmmm, this is the search part,
// really the third level of select(rollup(search...)...)
expression = StreamExpressionParser.parse(search_expression);
CloudSolrStream searchStream = null;
RollupStream rollupStream = null;
SelectStream selectStream = null;
TupleStream stream = null;
// OK, let's set the innermost stream up.
try {
searchStream = new CloudSolrStream(expression, factory);
searchStream.setStreamContext(streamContext);
// What is this about? I have to change the metrics
// time I change the expressions I want to collect?
// this is an example of how to instantiate
// "rollup_parameters".
Bucket[] buckets = {new Bucket("something")};
Metric[] metrics = {
new SumMetric("some_field1"),
new MinMetric("some_field2"),
new CountMetric()};
// I need to revisit this if the expression changes?
rollupStream = new RollupStream(searchStream, buckets, metrics);
rollupStream.setStreamContext(streamContext);
// Set the rest of the parameters I need to set for rollupStream.
// What are they? How do I do that?
// Do I need to revisit this if the select changes?
// Now wrap the above in the outermost SelectStream
selectStream = new SelectStream(rollupStream, more_parameters_what_are_they);
// Is it OK to set the streamContext to the same underyling object for all
// three streams?
selectStream.setStreamContext(streamContext);
// set any additional necessaries.
stream = selectStream;
} catch (Exception e) {
// handle all of the bits I need to here. Closing the streams?
// Are they open? The usual issues with catch blocks.
}
// Oops, I caught the exception above, I guess I have to test here for
// whether the stream is null.
try {
stream.open();
read_tuples_til_EOF;
} catch (Exception e) {
//report an error
} finally {
// try/catch in a finally block just in case
// something goes wrong.
if (stream != null) {
try {
stream.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
// Hmmm, what is this solrClientCache anyway?
// Oh, I set this cache for all the streams I created,
// do I have to close it three times (no)?
// All I know experimentally is that my SolrJ program will hang
// for 50 seconds if I don't do this when I try to exit.
// I guess I could look through all the code and understand this
// in more detail, but the boss wants results.
solrClientCache.close();
Ok, the above is a little over the top but you get the point. There are many considerations involved in getting the entire Streaming Expressions code to perform the miracles that it does. And rather than have all this done for you, you’ll have to adapt your code for every change in the Streaming Expression; say you want to add the “max(some_field3”), or write some generic builder. And do this once you have already worked out the expression you want in the first place. That’s already all done for you by the simple pattern above.
Were I to put on my curmudgeon hat, I’d claim that it would be nice if these low-level constructs were concealed from SolrJ clients. SolrJ is what’s used for the communication between the Solr node, so this level must be exposed.
We never did make the above code work completely. Eventually we ran into another layer of difficulty. Whether it was because the code used the “qt=/export” rather than “qt=/stream”, or some such — we had some other mistake or the moon wasn’t full I don’t know. What I do know is that when I was provided with the recommended solution and started thinking about maintaining “roll your own” I realized that the benefit of using the recommended pattern far, far outweighed rolling our own. Not only from a “let’s get something out the door” perspective, but also from a maintainability perspective.
Rolling your own is unnecessary. The recommended pattern bypasses all of the complexity and leverages the work of the people who really understand the underpinnings of Streaming Expressions. I strongly recommend that you use the recommended pattern and only venture to lower-level code patterns if you have a compelling need. And, quite frankly, I’m having difficulty dreaming up a compelling need.
Other gotchas
And then there are the “extra” problems:
The above code gets the ZK ensemble. Seems simple enough. But what if I’m using some deployment that doesn’t let me access the ZooKeeper ensemble? I can use http requests via tunneling much more easily
Admittedly the Streaming Expression strings are “interesting” to construct. Using the recommened pattern allows you to use arbitrary Streaming Expressions rather than having to revisit your code every time the expression changes.
Conclusion
Some very smart people have spent quite a bit of time making this all work, handling the gritty details and are maintaining this going forward. Take advantage of their hard work and use the recommended pattern!
[1] I want to particularly call out Joel Bernstein, one of the main authors of the Streaming concept who has been extremely generous when it comes to answering my questions as well as questions on the user’s list. Let’s just say he makes me look a lot smarter! I haven’t totaled up how much the bar tab I owe him amounts to, but it’s sizeable.
It wasn’t long ago that search technology was stagnant. The hard problems back then were data connectivity and import. Search teams might still struggle with these challenges for specific projects, but they are broadly solved from a technology standpoint. The next set of problems are about language parsing, how to stem words and match up to keywords, phrase matching, and faceting. There is always another tweak, but nearly every search product on the market does those things.
In recent times, search technology came alive with open source technology that allowed it to scale to big data sizes and brought web-scale to every company that needed it. However, as technology has progressed and the amount of data increased, so has our need to find the information we need in a mountain of data. Search technology is exciting again and here are the changes we can expect to see in the coming year!
Personalization becomes extreme
The new frontiers are not in connecting to yet another datasource or how to chop up a word or sentence. The new challenge is to match the results to the person asking the question. Doing this requires gathering more than a collection of documents and terms. It means capturing human behavior and assembling a complete user profile. That profile may be related to their profession (accounting vs sales/marketing vs engineering). That profile may be related to their past searches or purchases. This capability is moving past vendors like Amazon and Google. Other retailers are now incorporating this technology, we can expect to see this find its way into enterprise search applications.
Search gets more contextual
Who I am, what I’ve done, and what I want are “personalization.” Where I am in terms of geography, mobile phone provide location or in what part of an application is “context.” Up until now, web applications that provide search tend to provide a simple context-less search box.
However, the bar is being raised. If you ask your mobile device to provide a list of restaurants you don’t mean “in the whole world,” you want “around me and open right now.” Meanwhile, while working all day on one customer account, when you type “contracts” or “contacts” into any corporate search bar, in most enterprise search applications you get back a list of all documents that have those keywords. That’s “dumb” and search should be smarter and show you files related to the account you’ve been working on all day. The capability is there and this year users are going to start to expect it.
Applications become search-centric
Companies tend to deploy their applications and then add in some kind of “search portal” or series of search applications that are functionally separate to try and tie the search experience and the app experience back together. This requires a lot of the user, they have to context-switch and go back to a different site. To minimize this friction, search is getting integrated into the core of most applications. Whether it be traditional stalwarts like your CMS or CRM or newcomers like Slack, search is no longer an afterthought, it is the main way to interact with the application. In 2018, this will become more of an expectation of internal- and customer-facing applications as well regardless of their use case.
Machine learning becomes ubiquitous
So much of what we do as human beings is grouping things together because they look somehow similar (clustering) and sorting things into categories (classification). So many business problems are one of projecting based on trends (regression). Search has long been used to group stuff together and finding that stuff has often meant dividing it up into classes. What is different is that we can automate that.
However, it goes beyond this. In an era of rampant fraudulent news, reviews and transactions, Machine Learning allows search to sort through to the most relevant and most real results. This isn’t a nice to have anymore for most retailers, financial services or customer service sites.
In healthcare and insurance similar types of diagnosis, claims, and notes can automatically be grouped. Across the board, as a user’s profile is filled out recommendations for that user or for similar items are a necessity in an era where there is more data than information.
Migration to the cloud begins in earnest
The sky is falling! Cloud, ho! Many organizations will cease to run their own data centers. If you make pizzas, you should just do that, not deploy servers all over the planet. With that said, there are legal and technical barriers that have to be overcome before we’re all serverless. Because search is needed behind the firewall as well as in the cloud, for some time we’ll see on-premise and hybrid solutions more commonly than all cloud. With that said, the weather report for 2018 is a partly cloudy when it comes to search. Expect fewer pure on-premise deployments as more companies turn to hybrid and cloud search installations.
Search application development becomes a solved problem
In 2017, most search application developers were still writing yet another web search box with typeahead and facets from the ground up. Forget some of the more advanced features that you can implement, if you’re still hand coding basic features step-by-step, you’re not getting to the finish line very quickly. Most basic features and capabilities for search applications have already been written and the components are out there pre-coded for you. Savvy developers will start to use these pre-written, pre-tested components and frameworks and make their tweaks where necessary rather than reinventing the wheel every time. In 2018, we’ll see the end of from-scratch search applications at least for standard and mobile websites.
Single Service Solutions will start to abate
This year there were a lot of “new” and “old but reimagined” search solutions that were aimed at just one task. For example a search solution just for Salesforce. For one, it is hard to see a future where there is a significant market for a solution that does little more than improve a feature that is already built in without that vendor just augmenting with the same functionality. These single service search solutions are going to go away. Data wants to be together. Search is more than just “find all customers with ‘Associates’ in the name.” In order to reach the next level of customer engagement and employee productivity and find the answers that you need, you need to be able to augment data with other data. To do this you need a search solution that supports multiple sources and use cases. Sure it was fun being able to add search to this service, but now you need more. You don’t really want to manage ten single service search solutions for multiple data sources and use cases. In 2018, expect to see some pushback on search solutions that only serve one use case or search one data source.
Search in 2018: Get started now
Search in 2018, is going to be more personal, contextual, spread through all of your applications, powered by machine learning, and in the cloud. In 2018, we’ll stop developing search UIs from scratch and start putting together components that are pre-written, pre-tested, and ready for prime time. In 2018, we’ll stop using single-service solutions and power our search with a solution that supports all of our use cases with multiple data sources.
Get a move on the new year with Lucidworks Fusion and Fusion App Studio. Consider signing up for Fusion Cloud. This will put you on the path to more personalized modern search applications and give you an excellent path through 2018 and beyond.
2017 was a big year in search technology. As we chronicled last month in our rundown of trends for 2018, search technology has moved far beyond just keywords, faceting, and scale. But let’s take a look back at the trends that have continued through the past year.
Continued Industry Consolidation
We’ve continued to see consolidation with the exit of Google Search Appliance from the market. Now organizations are re-evaluating technologies, like Endeca, that have been acquired by vendors and products like FAST and have been embedded in other products. Ecommerce companies that have traditionally thought of search as a primary part of what they do, have already migrated to newer systems. In 2017, IT companies stuck with maintaining technology not intended for today’s scale, moved away from legacy technologies in earnest.
Meanwhile other vendors have been downsizing staff but continuing to support the locked-in long tail installation base. You can figure out which ones by looking at current vs past employees on LinkedIn. In 2017, customers started to get wise. No one wants to be the last one on a sinking ship.
In this same time period, I’m proud to say Lucidworks continued to grow in terms of code written, revenue, employees, and even acquisitions.
Technology and Data Consolidation
Not long ago, larger companies tended to have more than one IT department and each of those individual departments had their own search solution. So there would be a search application for sales which was deployed by the sales IT group and then another search app for the HR department deployed by their IT group and then probably yet another search solution for the product teams built by their IT group. With IT consolidation, an ever-increasing mountain of data, and new integrated business practices, there is a greater need than ever to consolidate search technology. There are still single source solutions (especially in sales) but last year, IT departments continued to push to centralize on one search technology.
Meanwhile there are more data sources than ever. There are still traditional sources like Oracle RDBMS, Sharepoint, and file shares. However, there are newer data sources to contend with including NoSQL databases, Slack, and SaaS solutions. With the push towards digital business, and turning information into answers, it is critical to build a common search core to pull data from multiple sources. In 2017, we saw continued movement in this direction.
Scale Out
Virtualization replaced bare metal for most companies years ago. The trend was the joining of the private and public cloud. This move continued against a business backdrop of continued globalization and a technology backdrop of continued mobilization. In 2017, modern companies often conducted business all over the world from palm-sized devices, tablets and laptops.
Meanwhile there are new forms of data emerging. Customers now generate telemetry from their mobile devices. Buildings can now generate everything from presence data to environmental and security information. Factories and brick-and-mortar storefronts now generate data forming the so-called Internet of Things. With machine learning and search technology, companies are now starting to make better use of this sort of data. These trends were nascent in 2017, but still observable.
In a virtualized, cloud-based global world where data is generated from everything everywhere all of the time, companies need search technology that can handle the load whenever, wherever, and however it comes. Old client-server technology was no longer enough to handle these demands. In 2017, horizontal scale was no longer a luxury, but a necessity.
Personalization and Targeting
2017 saw simple search start to abate. While AI and machine learning technologies are relatively new to the search market, some of the more mature tools saw widespread deployment. Many organizations deployed search technology that could capture clicks, queries, and purchases. Modern search technology use this information to provide better, more personalized results.
Collaborative filtering (boosting the top clicked item for a given query) is the most common optimization followed by similarity (MoreLikeThis) but we also saw companies start to deploy Machine Learning powered recommendations especially in digital commerce. These recommendations use information about what a user or similar users have done to suggest choices.
Mainly Custom Apps, but The Rise of Twigkit
In 2017 most companies were still writing their own custom search apps. Unlike previous years, these apps are very AJAX/JavasScript-y/dynamic. Frameworks like Angular ruled the search application market. At the same time, savvy organizations realized that writing yet another search box with typeahead was a waste of time and they started using pre-built components. One of the best toolboxes of pre-tested pre-built components was Twigkit.
Twigkit had been around since 2009 and was a widely respected force in the search industry with relationships with all of the major vendors and customers all over the world. Lucidworks had been recommending it to our customers and even using it in some deployments so we decided to acquire the company and accelerate the technology. The future of Twigkit was announced as at our annual conference last September with the technology becoming part of Lucidworks App Studio.
Happy New Year
Goodbye to 2017 but hello to 2018. It was a great year for search, but not as good as what is coming. If you want to see what’s on the way in 2018, here’s my take on what to watch for in the coming year.
It is important to understand the risk of this bug, but not to overestimate it. To operate, the exploit needs to be already running inside of software in your computer. It does not allow anyone on the internet to take control of your server over http, for instance. If there is an existing vulnerability, it does make it worse as the vulnerable process might be used to read memory from other processes.
There are already operating system patches out for this bug. Unfortunately, the operating system level patch for this bug requires creating a software isolation layer which will have a significant impact on performance. Estimates are that its impact can be between 5-30%. Every piece of software running in the Application space may be affected. The impact will vary, and each application will need to be performance and load tested.
Some customers running on their own internal hardware may decide that, given the vector of the exploit and the performance cost of the fix, they may decide to delay applying it. Other customers running on more vulnerable environments or with more specific security concerns may need to apply it and deal with the performance implications.
Fortunately for Lucidworks customers, Fusion and its open source Solr core are especially adept at scale. For high capacity systems, the most cost-effective solution may be to add a number of additional nodes to allow for the increased weight of the operating system. Additionally, by tuning the Fusion pipeline it may be possible to reduce the number of calls necessary to perform queries or parallelize some calls thus compensating for the loss of performance through optimization in other areas.
In either case Lucidworks is here for our customers. If you’re considering applying the fix, please reach out to your account manager to understand ways that we can help mitigate any issues you may have. If you do not currently have or know your account manager, please file a support request or use the Lucidworks contact us page.
In a global economy there is no downtime. Even for national or local retailers, downtime has become a thing of the past. People buy at odd hours. Customers who have a bad experience have other options that are up 24×7. Search is the core of the Internet and even more so the core of how people buy things on the Internet.
24×7 Core Infrastructure
Despite this, many e-commerce platforms and even dedicated search solutions treat availability as an afterthought. One well-known search solution actually requires you to store everything and scale a NAS in order to achieve availability. Not only will that not scale, but it isn’t very dependable.
Lucidworks Fusion is built upon a Solr core architecture. This architecture is tried and true and is the same general idea that the Internet giants use to scale to great size while simultaneously maintaining what used to be uncommon uptime.
Meanwhile the world is becoming more volatile. Whether it is climate change making weather patterns more erratic, violence around the world, or just plain old fiber cuts, you need to make sure you can handle a data center or cloud “Availability Zone” going down. This is known by many names such as Disaster Recovery, WAN replication, and CDCR. The bottom line is you need to stay up, no matter what!
24x7x365 Analytics
Recently everyone is getting into the personalization and analytics/data science business. Supposedly you’re going to profile your customers, send that off to a team of data scientists who are going to load that into notebooks, and they’re going to send you back something actionable. There are a lot of crickets in that.
With Fusion Insights you can see this kind of customer profile information out of the box, in real-time, whenever you want. Combined with our advanced AI technology you can also automate most of what you’d do using this data out of the way. From promotions to recommendations, you can automatically find the user their exact desires.
And yes, if you want you can just grab the user events into plain old Excel (or your favorite analytics tool) or query it with plain old SQL.
24x7x365 Updates
Stuff is happening, inventory is being received. You need a system that doesn’t need to go down for batch updates. You need an architecture that can be updated in real-time. If you have other systems that operate in batch, you need to be able to share the load and get it done as soon as inhumanly possible. If not, you’re losing real money.
Fusion’s Solr architecture is architected like the Internet. It can take streams of data at real-time speeds and make it readily available for your customers. Meanwhile, Fusion’s ingestion architecture can take and transform data using distributed computing technology so that as many nodes as possible are involved in getting the work done. This means your data is updated and ready as fast as you need it to be.
24x7x365 Changes
Data Sources change, customers change, and therefore systems change. A modern retailer is tweaking their algorithms for product search relevance, customer personalization, and everything in-between. A modern e-commerce search solution needs to be open to change at any time.
Fusion’s Query Workbench lets your search developers see what they’re doing and test it. Fusion’s Index Workbench even lets you change the way you import data and see what those changes will mean before they are live. Fusion’s Experiments engine allows you to do real A-B testing, allowing you to see which version of a query or customer targeting method yields more sales.
24x7x365 Search UI Development
Supposedly every time you want to make a change you’re supposed to have a JavaScript developer wind through a mountain of code and add some new functionality (type-ahead or recommendations, promotions, whatever). This is the way we’ve always done it in the Interweb era. However, it is a lot slower than the client-server days where you could drag-and-drop a WYSIWYG interface. Besides, surely someone has developed nearly everything we can think of by now. Why can’t your e-commerce search be “Legoware” and just rapidly re-arrange the blocks when it is time to update the interface?
As it turns out, you’ve got one up on the whiz-kid JavaScript developer. Lucidworks has already written nearly any advanced feature of your search UI that you can think of. It is a matter of wiring the right components together and putting your skin on. When it is time to change, move stuff around or add new components. Again, you need to be able to change your site at any moment and with rapid turn around. Fusion App Studio lets you do just that.
Fusion is your 24x7x365 Search Solution
You’ve got to stay up, accept changes to data, your system, and your UI at anytime while providing the most personalized tailored customer experience that the Internet allows. Lucidworks Fusion is built on the right architecture and has the right tools to let you do that.

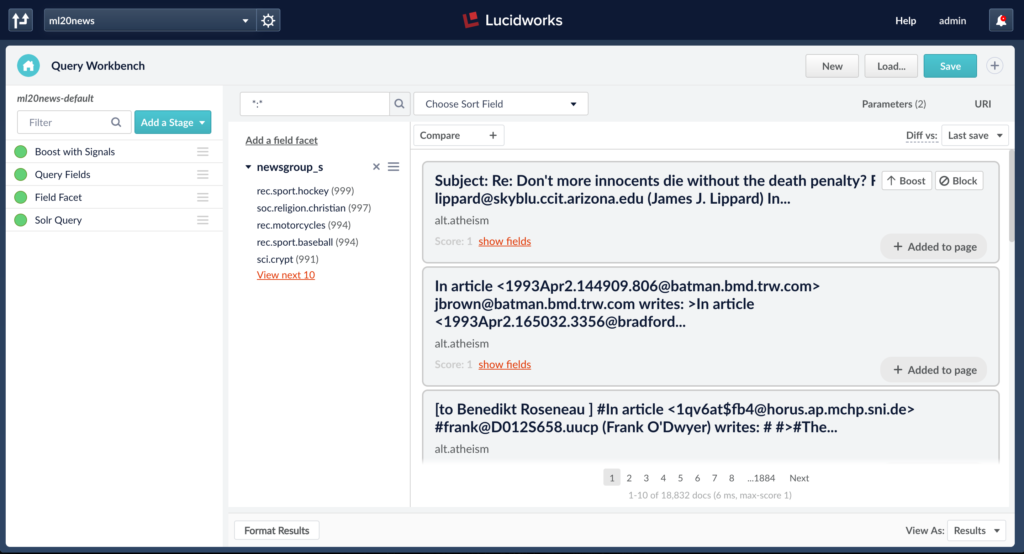
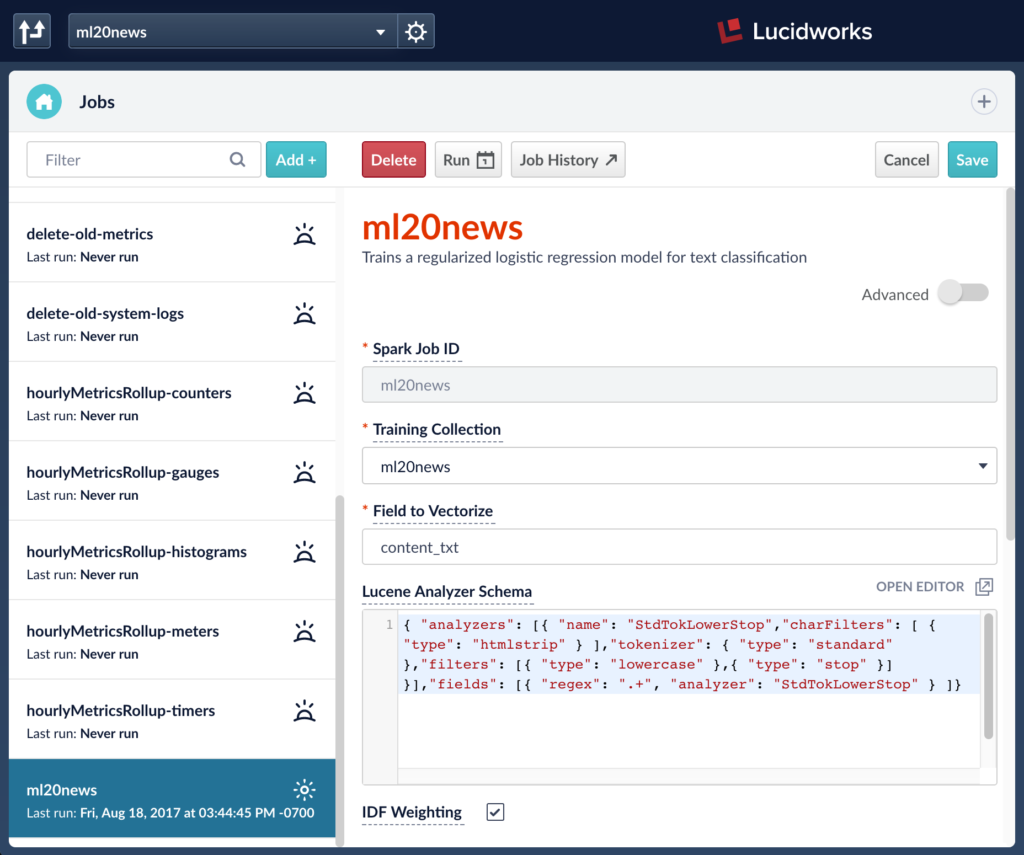
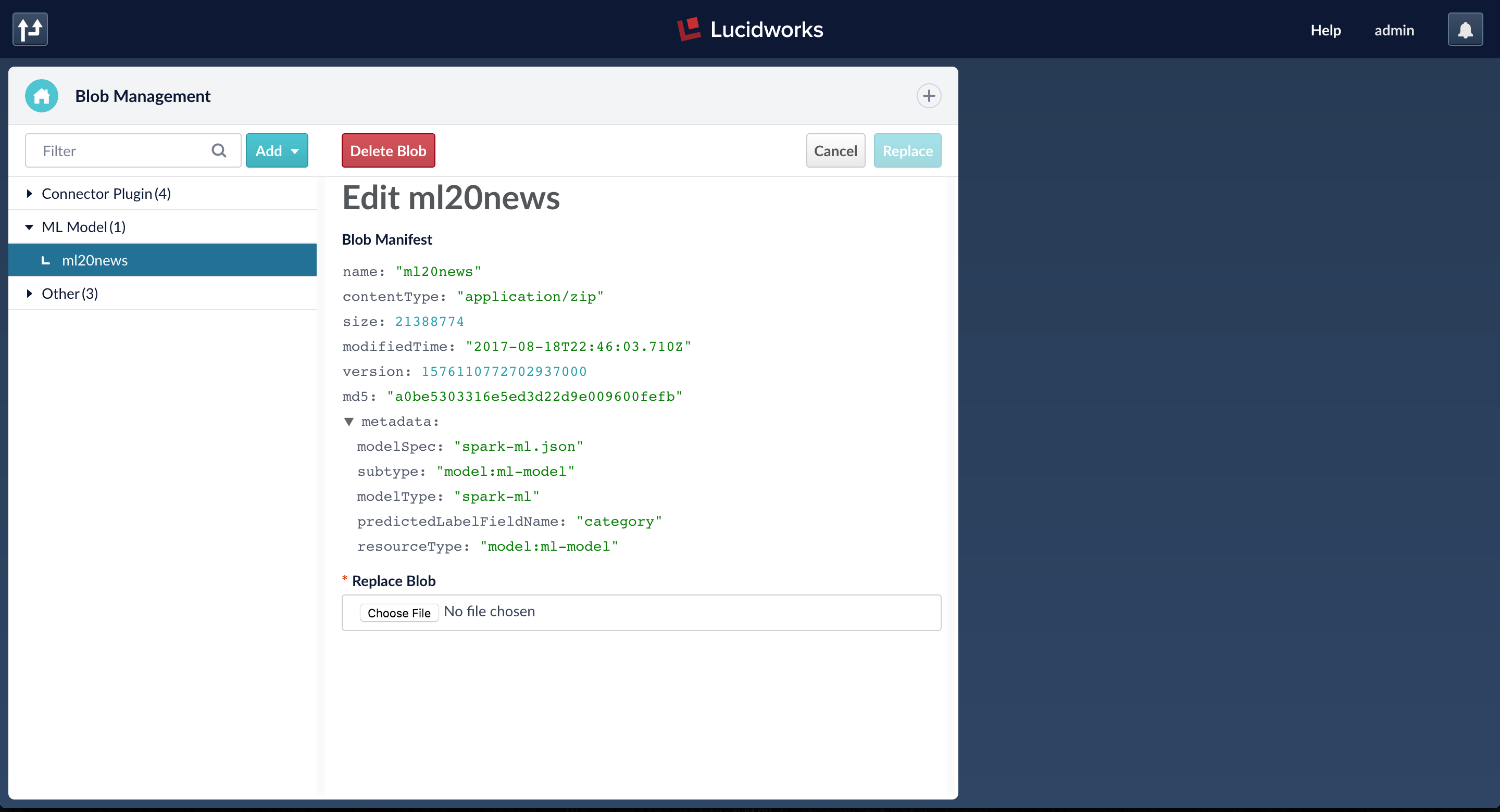
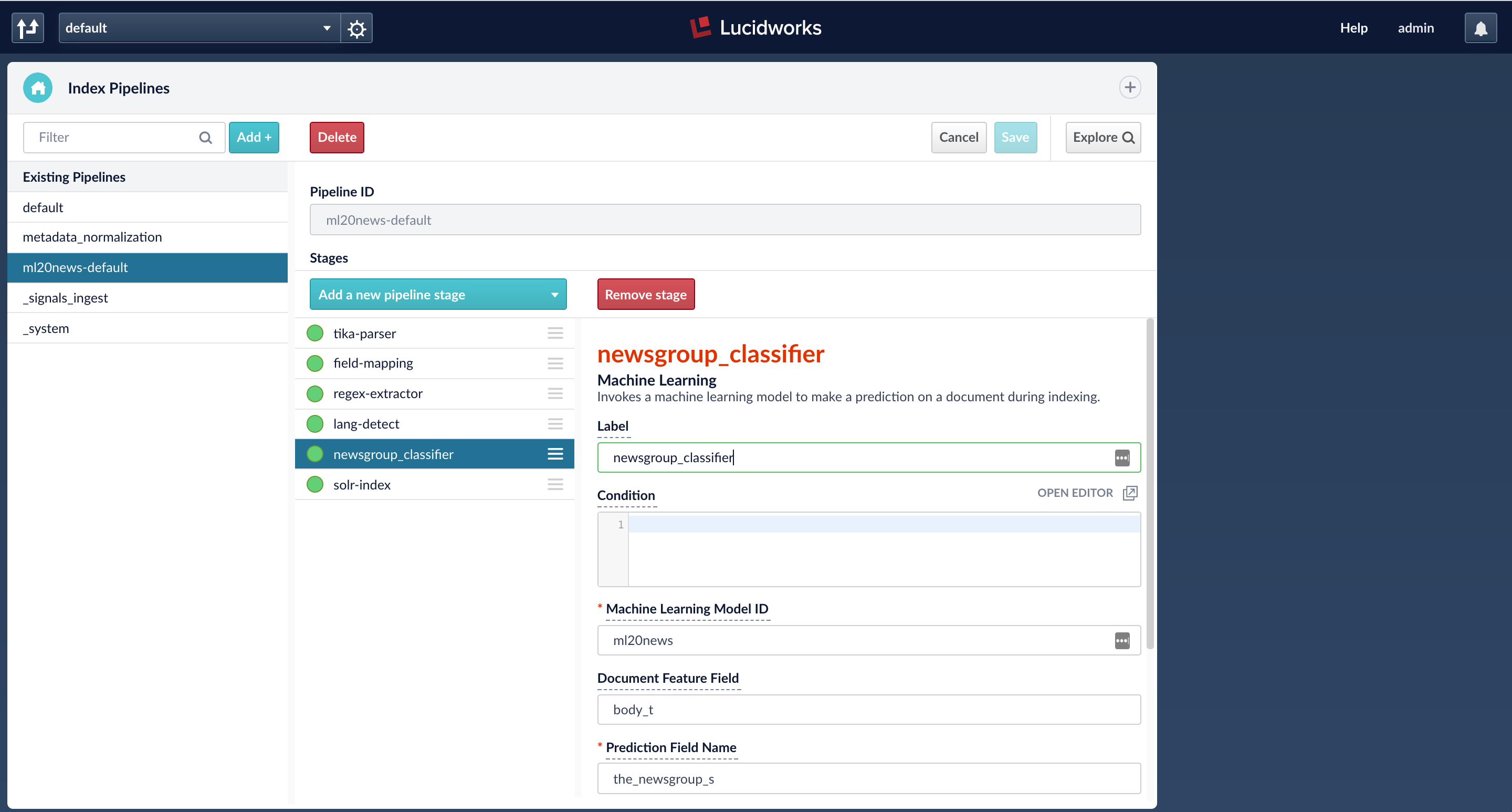
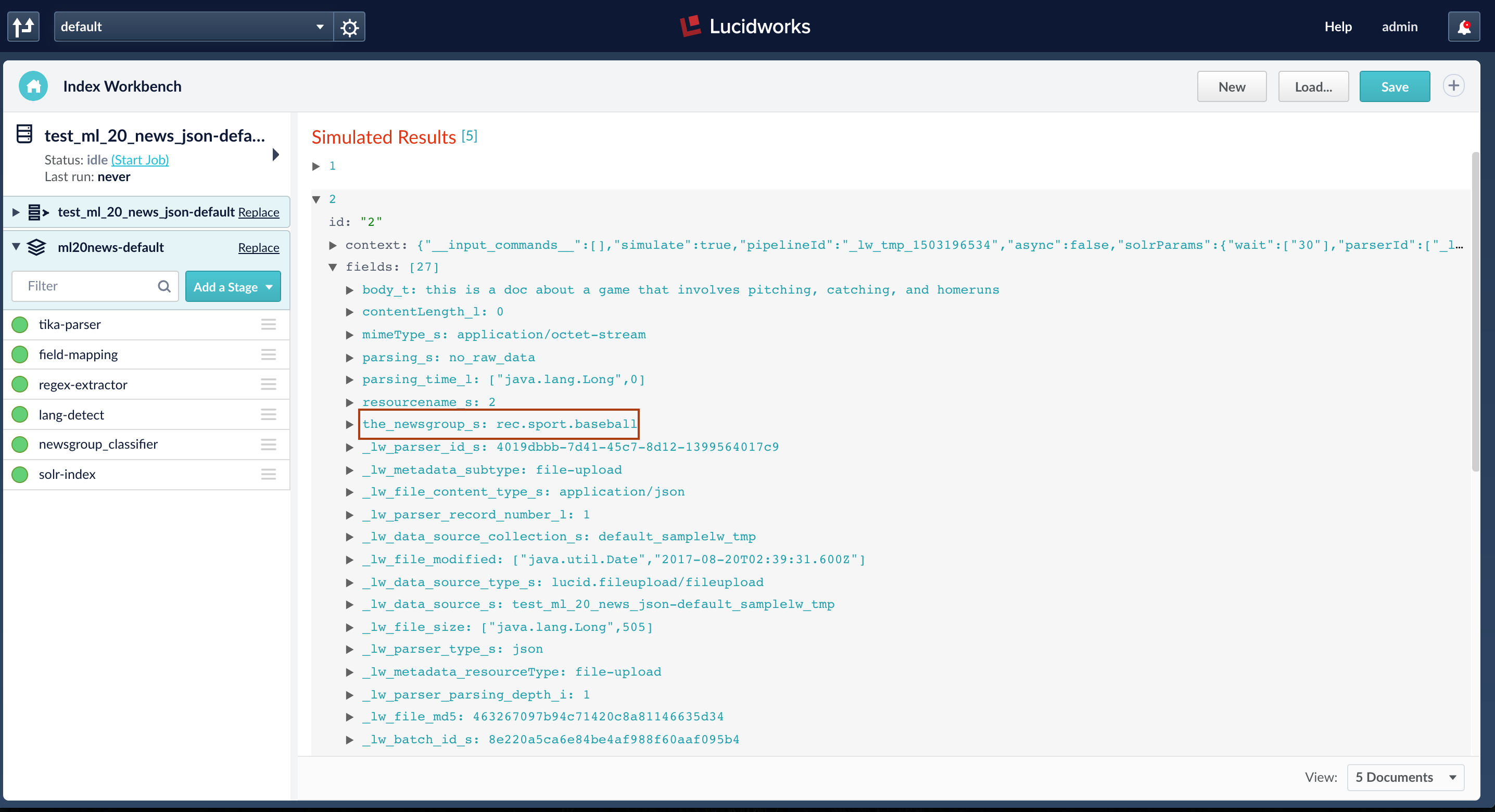







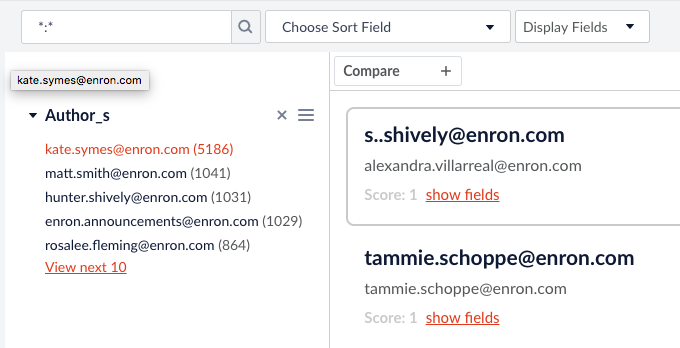


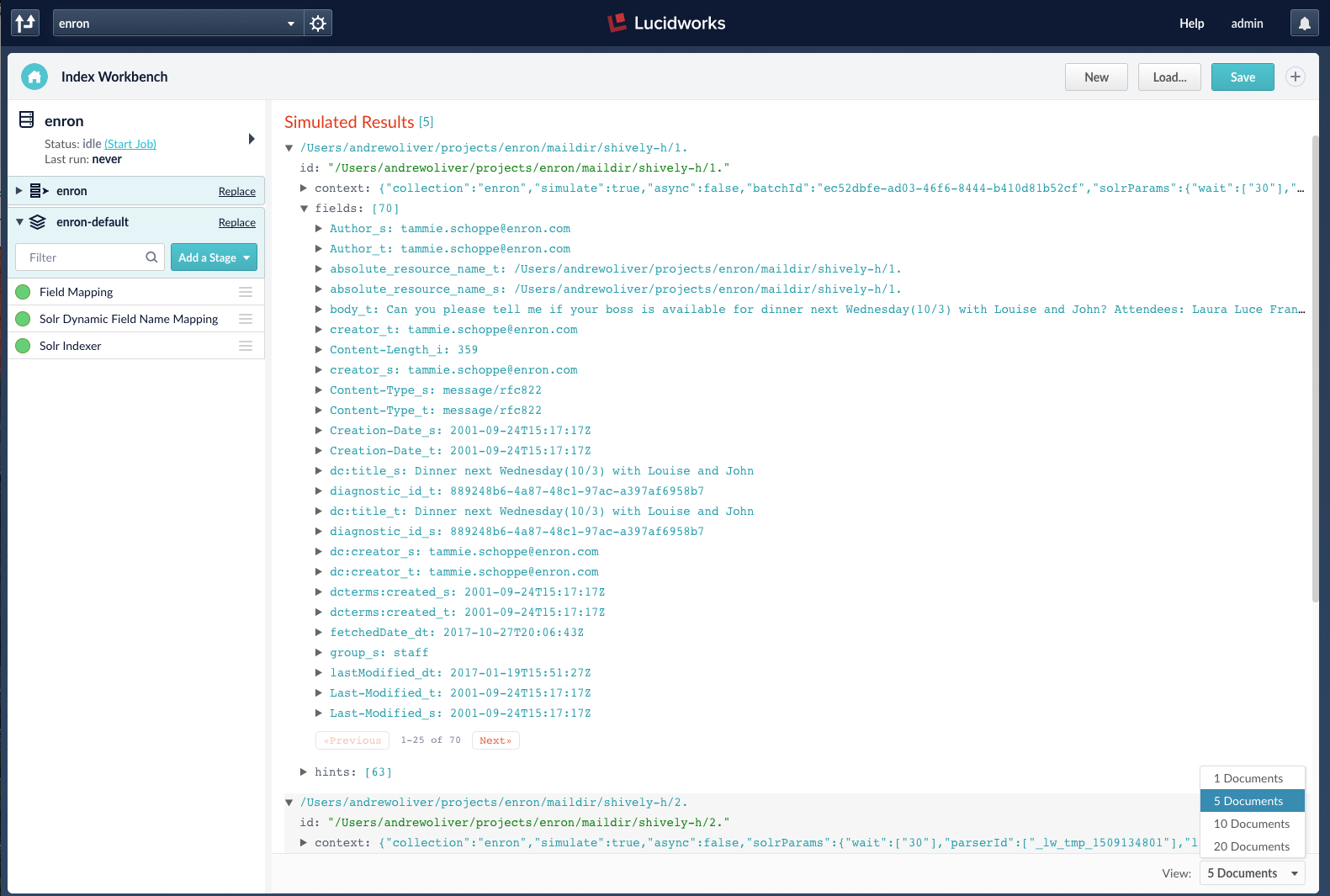
 Back in the day you had to learn to construct a search for Google. Now Google kinda knows enough about your past behavior, social networks, and geography to predict what you’re actually looking for. This personalization of search is no longer a luxury but essential to satisfy modern users.
Back in the day you had to learn to construct a search for Google. Now Google kinda knows enough about your past behavior, social networks, and geography to predict what you’re actually looking for. This personalization of search is no longer a luxury but essential to satisfy modern users.










