We are living in a time when the fields of Artificial Intelligence and Search are rapidly merging – and the benefits are substantial. We can now talk to search applications in our living rooms, cars, and as we walk down the street looking for nearby places to eat. As both fields mature, their convergence, while inevitable, is creating new sets of opportunities and challenges. Our Lucidworks Fusion product – especially the latest Fusion 4.0 release – is right in the middle of this latest search revolution. Its core technologies, Apache Solr and Apache Spark provide exactly the right resources to accomplish this critical technological merger. More on this later.
The Search Loop – Questions, Answers, and More Questions
At their core, all search applications, intelligent or otherwise, involve a conversation between a human user and the search app. Users pose questions and get an answer or a set of answers back. This may suffice or there may be follow-up questions – either because the initial answers are unsatisfactory or to obtain more detailed information. A critical component of this “search loop” is the initial translation from “human query language” to computer database or search engine lookup code. At the cutting edge are speech-driven interfaces such as Apple’s Siri and Amazon’s Alexa in which one simply talks to the search app (prefacing the question with her name to wake her up), asks a question, and gets an answer back in a state-of–the-art text to speech rendering. Under the covers, the Siri or Alexa software is first converting your speech to text, then parsing that text to ascertain what you are asking. They do a very good job with questions formatted in ways that their programmers anticipated, less well with more open ended questions that naïve users tend to pose. It is clearly Artificial Intelligence, but not yet the ultimate AI envisioned by Alan Turing some 68 years ago. The Alexa developers know this too. When I asked Alexa if she could pass the Turing Test, she rightly responded: “I don’t need to pass that. I’m not pretending to be human.” Fair enough. Kudos to the Alexa team for both honesty and some amazing functionality.
Query Parsing – Inferring User Intent
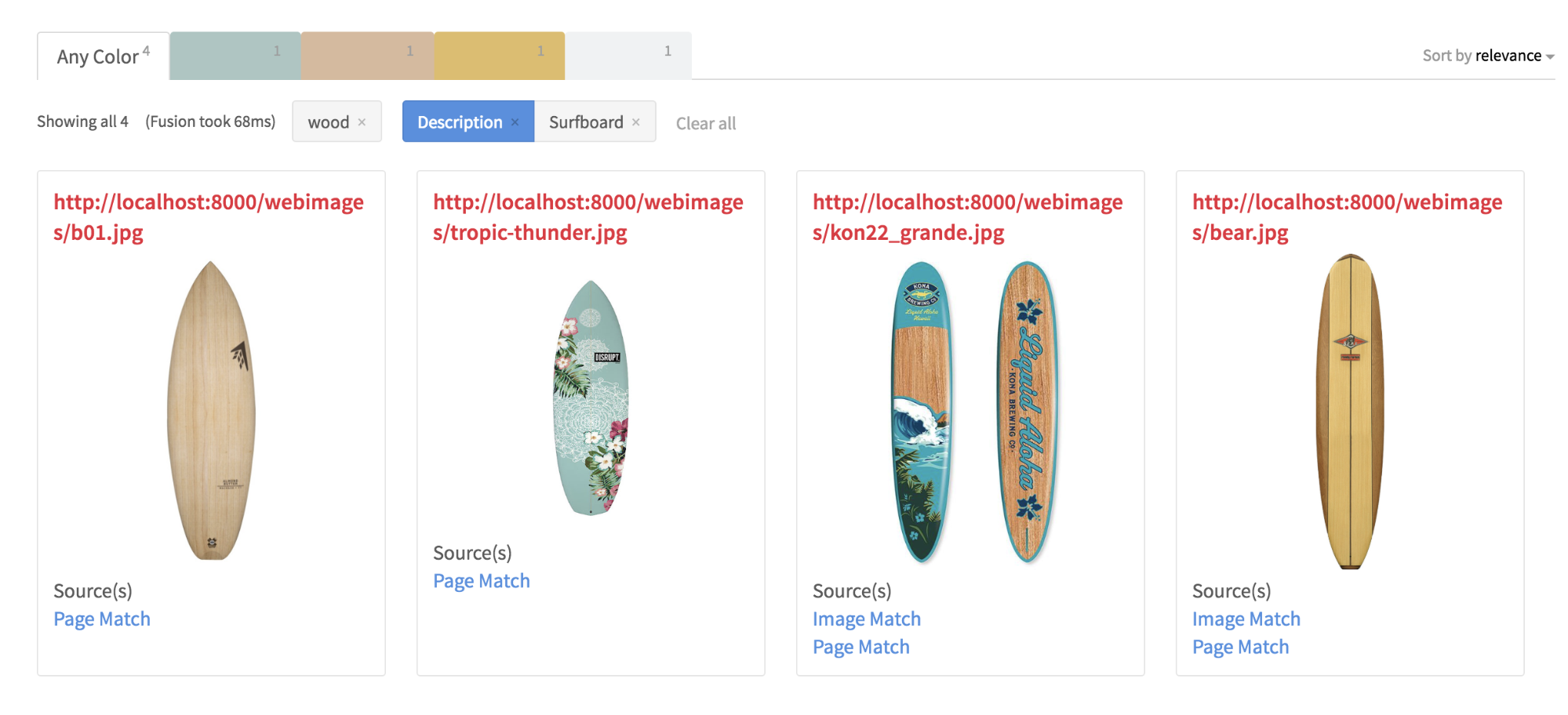
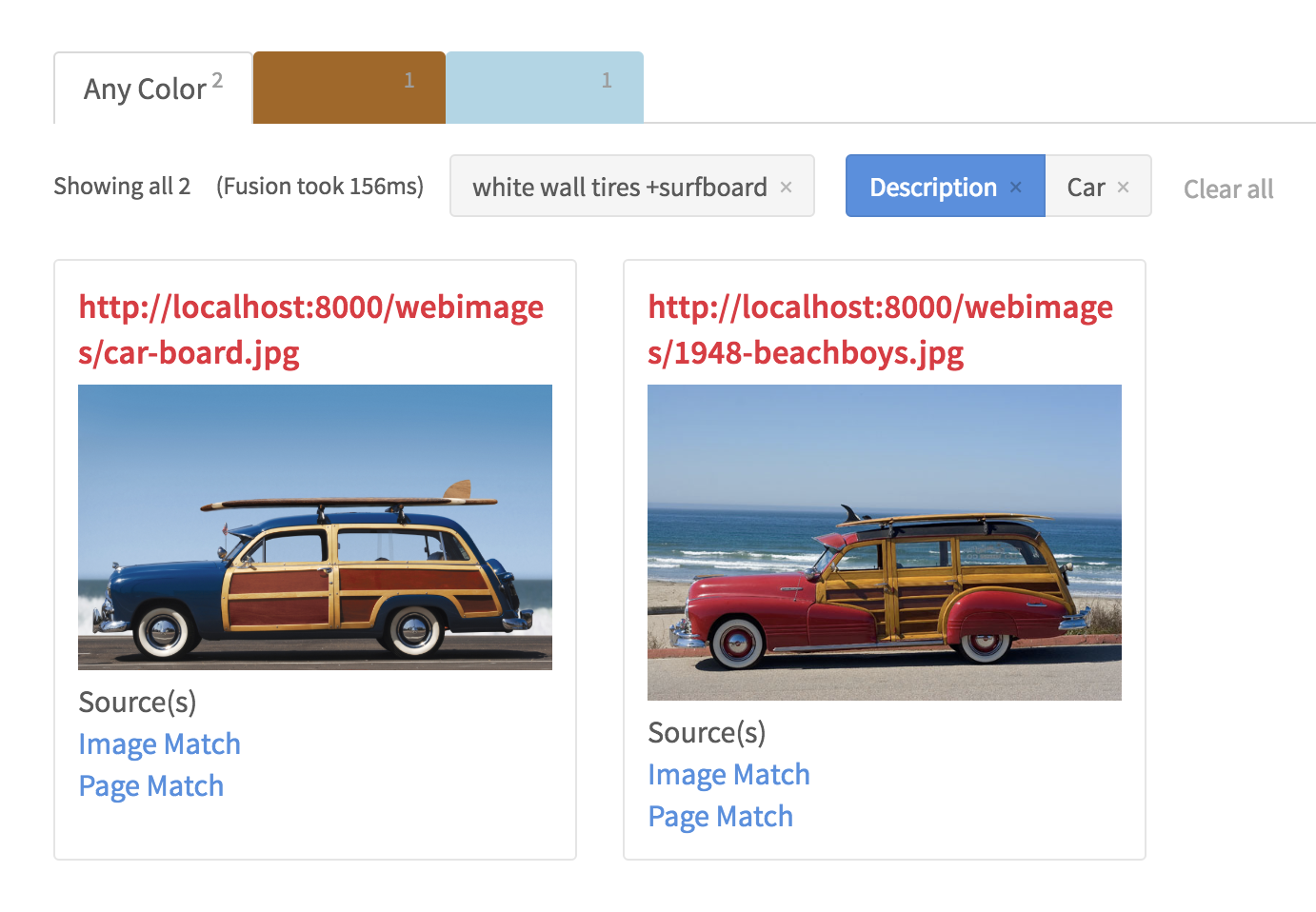
One of the driving motivations for adding AI to search is the realization that better answers can be given if we can do a better job of determining what the user is asking for. A critical component of this is a technology called Natural Language Processing or NLP. NLP works best when it has full sentences to work with, and in traditional search apps (i.e. not speech driven) this is often not available as users tend to put single terms or at most 3 to 4 terms into a search box. In some domains such as eCommerce, user intent is easier to infer from these short queries, as users tend to just put the name of the thing they are looking for. If this doesn’t bring back what they want, they tend to add modifiers (adjectives) that more fully describe their intent. Entity extraction, rather than Parts-of-Speech (POS) analysis becomes more relevant to this particular query parsing problem due to the lack of complete sentences. Machine learning models for entity extraction are part of the toolset used here, often based on training sets derived from query and click logs or by head-tail analyses to detect both the noun-phrases that directly indicate the “thing” (which tend to dominate head queries) and the added modifiers and misspellings that users sometimes insert (tail queries) – see Chao Han’s excellent blog post on this.
Another often used technique that is similar to what Siri and Alexa seem to do, is “directed “ or “pattern-based” NLP, in which common phrase structures are parsed (example “leather cases for iPhones” or “wireless cables under 30$”) to determine what is being searched for and what related attributes should be boosted. Pattern-based NLP does not involve complex linguistic analysis as is done with POS taggers. Rather it can be based on simpler techniques such as regular expressions. The downside is that it only works on expected patterns whereas more sophisticated POS taggers can work with any text. As noted above, in the latter case, user queries tend to be too cryptic to support “true” NLP. Extraction of entities as phrases is very important here, as this vastly improves search precision over the naïve “bag of words” approach.
In addition to ML-based approaches, another method for query intent inference which I have developed and blogged about called Query Autofiltering (QAF)[1,2,3,4], uses structured metadata in the search collection to infer intent – where term meanings are known based on their use as field values in the collection (e.g. “red” is known to be a Color because it is a value in the Color facet field). QAF requires highly structured metadata to work well and can benefit from techniques such as text mining at index time to provide better meta-information for query parsing of user intent. In particular, a critical piece of metadata in this respect – product type – is often missing in commercial datasets such as Best Buy and others, but can be mined from short product descriptions using NLP techniques similar to those discussed above. The use of synonyms (often derived from query logs) is also very important here.
Information Spaces – From Categorical to Numerical and Back
Search is an inherently spatial process. When we search for things in the real world like misplaced car keys, we look for them in physical space. When we search for information, we look in “information space” – a more highly dimensional and abstract concept to be sure, but thinking about the problem in this way can help to conceptualize how the various technologies work together – or to put it more succinctly, how these technologies map to each other within this information space.
Databases and search indexes are metadata-based structures that include both categorical and numerical information. In traditional search applications, metadata is surfaced as facets which can be used to navigate within what I call “meta-information space.” As I discussed in a previous blog post, facets can be used to find similar items within this space in both conventional and unconventional ways. Hidden categories also exist in “unstructured” text and the surfacing of these categorical relationships has long been a fertile ground for the application of AI techniques. Text analytics is a field by which free-text documents are categorized or classified – using machine learning algorithms –bringing them into the categorical space of the search index, thereby making them easier to search and navigate. The process is an automated abstraction or generalization exercise which enables us to search and navigate for higher level concepts rather than keywords.
In contrast to meta-informational data structures used in search applications, machine learning algorithms require purely numerical data, and model information spaces as n-dimensional vectors within continuous or numerical Euclidian spaces. For this reason, the first operation is to “vectorize” textual data – i.e. translate patterns in text to a purely numerical representation that machine learning algorithms can work with. This traditionally involves determining frequencies and probabilities of text “tokens.” A common metric is term frequency / inverse document frequency or TF/IDF. This metric is also the basis of the Lucene search engine’s default Similarity algorithm (the current default BM25 algorithm adds some “tweaks” to deal with things such as document length but maintains TF/IDF at its core). The assumption here is that “similarity” in conceptual space can be modeled by “closeness” or proximity of term vectors in n-dimensional numerical space. The proof of this assumption is in the pudding as it were – the success of machine learning approaches generally validates this basic “leap of faith” in traversing between categorical and numerical spaces.
The machine learning “loop” involves translating textual to numeric information, detecting patterns using mathematical algorithms, and finally translating the resulting matrices of numbers back to predictions (e.g. predicted memberships in categories), given a new document that the pattern detecting algorithm has not yet encountered. The artifact produced by the pattern detection step is called a “model.” Creating good machine learning models is both an art and a science, meaning that the work of “data scientists” will continue to be in great demand.
There are two main types of machine learning algorithms, which basically differ in the source of the label or category that is mapped by the algorithm. With “unsupervised” learning algorithms such as Latent Dirichlet Allocation (LDA) or KMeans, the categories are automatically discovered from patterns in the data. Typically, this involves finding “clusters” of terms that tend to be co-located in documents in a statistically significant fashion. Applying a higher level label to these clusters is often difficult and may be augmented by inspection by human experts, after the automated clustering is done. In contrast, with “supervised” learning, the labels are provided by subject matter experts up front as part of a training set. The human supplied labels are then used to detect patterns in the training data that correlate to the labels, to create a model that can be used to predict the best category or label given a new unclassified document. By this means, the work of the subject matter expert in manually categorizing a small training set can be scaled to categorize a much larger corpus. The accuracy of the model can be tested using another set of human-tagged documents – the test set.
Word Embedded Vectors – Direct Modeling of Semantic Space
Another machine learning technique that is rapidly gaining ground in this field are algorithms such as Word2Vec, FastText, and GloVe that can discover syntactic and semantic relationships between terms in a document corpus using statistical analysis of term relationships, by scanning large amounts of text (with tens or hundreds of billions of terms). The output of these algorithms are known as “word embedded vectors” in which terms are related to other terms within a multi-dimensional vector space computed by the machine learning process, based on their distance (Euclidian or angular) from each other in this space. As with other forms of machine learning, the fact that semantic categories have been learned and encapsulated within the sea of numbers that constitutes the trained model (i.e. the “black box”) can be shown by probing the model’s outputs. Given a term’s learned vector, we can find its nearest neighbors in the vector space and these near neighbors are found to be highly syntactically or semantically correlated! The relationships include synonymous terms, adjective relationships (big -> bigger -> biggest), opposites (slow -> fast), noun phrase completions, and so forth. Other semantic relationships such as Country -> Capital City are encoded as well.
The value here is that the vectors are both categorical and numerical providing a direct mapping between these different representations of information space – thereby showing the validity of such a mapping. The mapping is a rich, multi-dimensional one in both numerical and semantic senses. The most famous example from the Google team’s Word2Vec work (also reproduced by the GloVe team) showed that the vector for “King” minus the vector for “Man” plus the vector for “Woman” yields a vector very close to the learned one for “Queen.” A “King” can be roughly defined as an “adult male with royal status.” Peeling off the “adult maleness” aspect of the “King” vector by subtracting the “Man” vector leaves its “royal status” context behind and when this is combined with the vector for “Woman” yields a resultant vector that is very close to the one that was learned for “Queen.” The vectors connecting word pairs that express some semantic category such as “gender opposites” like “father, mother”, “brother, sister”, “uncle, aunt”, “son, daughter” etc. are seen to be roughly parallel to each other within what can be thought of as a “semantic projection plane” in the space. However, the examples above have more than one “semantic dimension” or classification category (e.g. parent, offspring, sibling, etc). This suggests that not only can semantic relationships be encoded mathematically, but that this encoding is composed of more than one categorical dimension! In their research paper on Word2Vec, Mikolov et.al put it, “words can have multiple degrees of similarity” and this multi-dimensionality in “syntactic and semantic space” is reflected in word vector space. That’s an impressive demonstration that we can use abstract mathematical spaces to encode categorical ones!
Among the related things that surface in word embedded vectors are noun phrase completions. For example, in an IT issues dataset, the term ‘network’ was found to be related to the words ‘card’ and ‘adapter’ and ‘failure’ However, if I train the model with phrases like ‘network adapter’ and ‘network card’ and ‘network failure’, the relationships will include these higher level semantic units as well. In other words, using noun phrases as input tokens turns “Word2Vec” into “Thing2Vec”. Similar observations are found in the literature.
Although interesting in and of themselves from a theoretical perspective, the results of word vector embeddings are proving to have great utility in other forms of machine learning. Recent research has shown that using pre-trained word vectors for other machine learning tasks such as document classification, spam detection, sentiment analysis, named entity extraction, etc., yields better accuracy over more basic vectorizations based on term frequencies. This make sense as moving from token based vectorizations, which have no knowledge of semantics, to vectorizations that have such embedded knowledge, improves the “signal-to-noise” of higher level text mining efforts.
Knowledge Spaces and Semantic Reference Frames
As we (humans) acquire language, first as young children and then as we continue our education (hopefully throughout life), we develop an internal “knowledge base” that we can use to disambiguate word meanings based on their context. For example, the term “apple” has multiple meanings as it can occur in several subject domains. The default meaning is the one known to our forbearers – that of a kind of fruit that grows on trees (horticultural domain). A secondary meaning that your great-great grandmother would also have known is as a food ingredient (culinary domain) as in “apple cobbler.” In our modern culture however, this term has obtained other meanings since it has been used a) to name a computer / tech company, b) to name a recording company of a famous popular music band and c) a nickname of a large city on the east coast of the United States. Which meaning is intended can be gleaned from context – if “apple” is in proximity to names of varieties such as “Granny Smith”, “Honey Crisp”, or “Golden Delicious” – we are talking about apples proper. If the context terms include “iPhone”, “OS X”, “iTunes”, “Steve Jobs”, or “Tim Cook” – we are talking about Apple Computer, and so forth. We use our knowledge of these contextual relationships between terms or phrases to orient ourselves to the appropriate subject domain when dealing with text. Linguists refer to this knowledge-based orientation as semantic reference frames.
Taxonomies, Ontologies: Knowledge Graphs
Giving this same ability to search applications enables them to better infer query intent and improve the relevance of search results. One famous example is IBM’s Watson – which learned millions of facts by scanning an enormous number of text documents, building a knowledge base that could then be used to play (and win) the TV game show Jeopardy. Watson used a framework that IBM open sourced called UIMA to first extract entities using Named Entity Recognition or NER techniques and then to extract facts by detecting semantic patterns of named entities. Performing a similar exercise on the query (NER + pattern detection) enabled Watson to plug the named entity variables (person:X book_title:Y) into a lookup to its knowledge base. The AI systems that are now infiltrating our homes and cars such as Google, Cortana, Siri, and Alexa use similar techniques. The key is to use some knowledge base to tag terms and phrases within a query or document so as to ascribe semantic meaning to them. Once this is accomplished, the rest is just like SQL. The Query Autofilter discussed above does a similar thing except that in this case, the knowledge base is the search collection itself.
Ontologies and taxonomies are types of “knowledge graph” – data structures that enable known facts and relationships to be codified – they are in other words, graphical representations of knowledge space. Taxonomies encode hierarchical relationships – either IS-A class / sub class (hypernym/hyponym) or HAS-A whole-part (meronym) relationships. Ontologies are more open-ended and encode knowledge spaces as a set of nodes that typically define entities and edges that define the relationship between pairs of nodes.
Taxonomies and ontologies have traditionally been manually created and curated. This has the advantage of accuracy but suffers in terms of completeness and currency (i.e. keeping it up to date). For this reason, machine learning approaches, while more error prone, are increasingly being used for knowledge mining. For example, the semantic frames approach that is used for user intent detection in queries and for pattern detection in text can also be used to build knowledge graphs. An example of this would be to take the text “NoSQL databases such as MongoDB, Cassandra, and Couchbase”, where the prepositional phrase “such as” or “like” implies that the things on the right are instances of the class of things on the left. These “lexico-syntactic patterns” are known as Hearst Patterns [Hearst 1992] and can be used to build taxonomies automatically via text analysis [e.g. TAXI]. Another approach is to couple metadata in a search collection with text fields to build graphs of related terms using a search engine like Solr. The resulting Semantic Knowledge Graph can then be used for a number of search improvement tasks such as “knowledge modeling and reasoning, natural language processing, anomaly detection, data cleansing, semantic search, analytics, data classification, root cause analysis, and recommendations systems” (Grainger et.al. 2016). From this example and the ones involving word embedded vectors (word2Vec, GloVe) – machine learning paradigms can be layered – creating outputs where the sum is greater than the parts.
If the output of the automated knowledge mining operation is something that humans can inspect (i.e. not a matrix of numbers), hybrid systems are possible in which subject matter experts correct the ML algorithm’s mistakes. Better still, if the ML algorithm can be designed to learn from these corrections, it will do better over time. Human-supplied knowledge base entries or negative examples gleaned from manual deletions can be used to build training sets that learning algorithms can use to improve the quality of automated knowledge mining. The development of large training sets in a number of domains is one of the things fueling this collision of search and AI. Human knowledge is thus the “seed crystal” that machine learning algorithms can expand upon. As my friend the Search Curmudgeon blogged about recently, in addition to data scientists, hire more librarians.
Although this exercise may never get us to 100% accuracy, once we get past some threshold where the computer-generated results are no longer routinely embarrassing, we can aggressively go to market. Although knowledgable search and data science professionals may be tolerant of mistakes and impressed by 85% accuracy, this is not so true of the general public, who expect computers to be smart and take occasional egregious mistakes as confirmation-bias that they are in fact not smart. As AI-powered devices are popping up everywhere we look now, that we have passed the general public’s machine intelligence “sniff test” is beyond question. As I mentioned earlier, while we are still a ways short of passing the gauntlet set by Alan Turing, we are clearly making progress towards that goal.
Lucidworks Fusion AI
So given all of this, what does our product Lucidworks Fusion bring to the table? To begin with, at Fusion’s core is the best-in-class search engine Apache Solr. However, as discussed above, to go beyond the capabilities of traditional search engines, bleeding edge search applications rely on artificial intelligence to help bridge the gap between human and computer language. For this reason, Apache Spark – a best-in-class engine for distributed data processing with built-in machine learning libraries was added to the mix as of Fusion 2.0 (the current version is 4). In addition to Spark, it is also possible to integrate other artificial intelligence libraries into Fusion such as the impressive set of tools written in the Python language such as the Natural Language Toolkit (NLTK) and TensorFlow. This makes building complex machine learning systems such as Convolutional Neural Networks or Random Forest Decision Trees and integrating them into a search application much easier. Fusion also provides ways to optimize ML algorithms by searching “hyper parameter” spaces (each model has tuning parameters which are often highly non-intuitive) using a technique called “grid search.” In short, while still benefiting from some data science expertise, Lucidworks Fusion puts these capabilities with reach of search developers that would not consider themselves to be machine learning experts. As of the latest release, Fusion 4.0, more intelligence has been “baked in” and this will continue to be the case as the product continues to evolve.
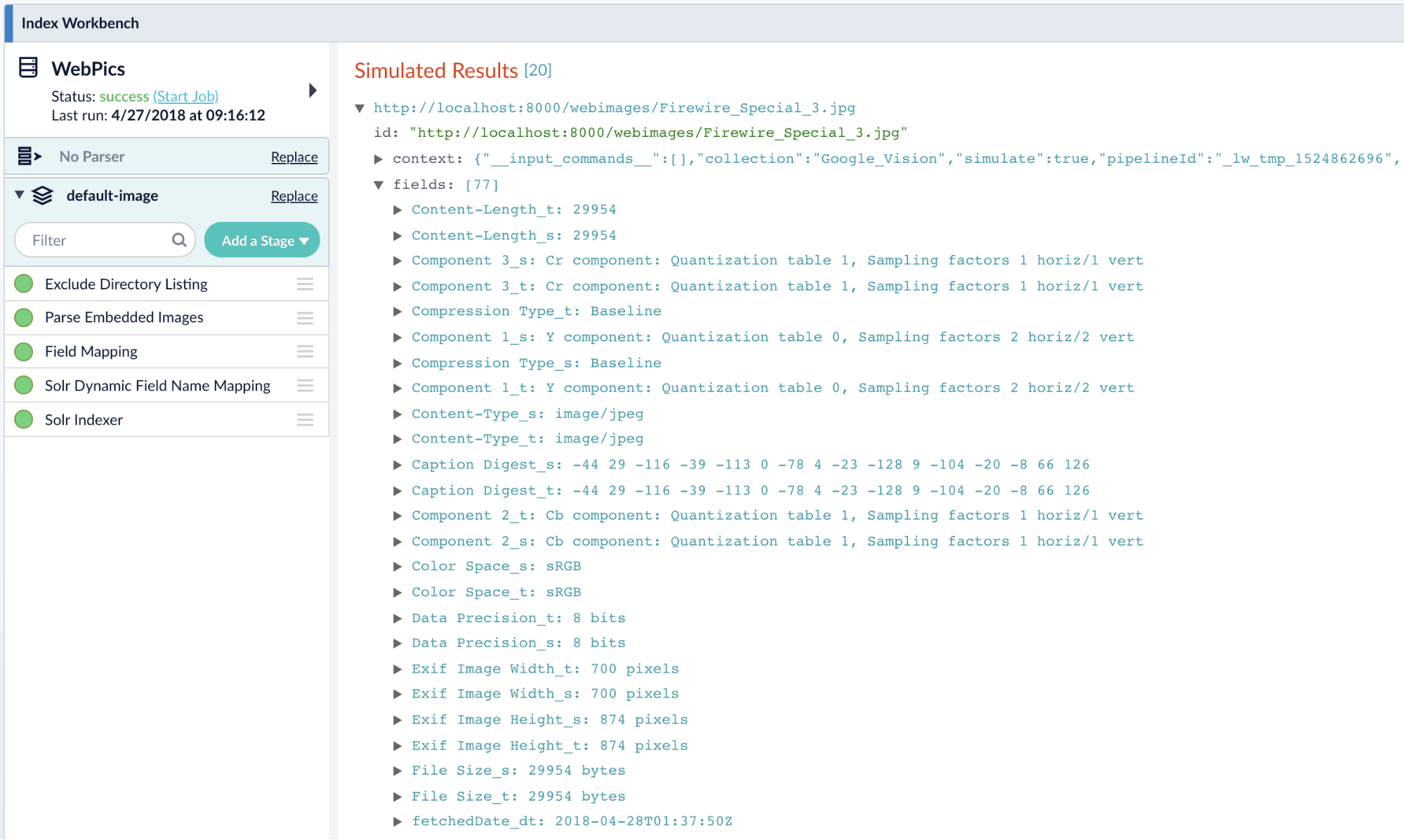
Machine Learning Jobs, Blobs, Index and Query Pipelines
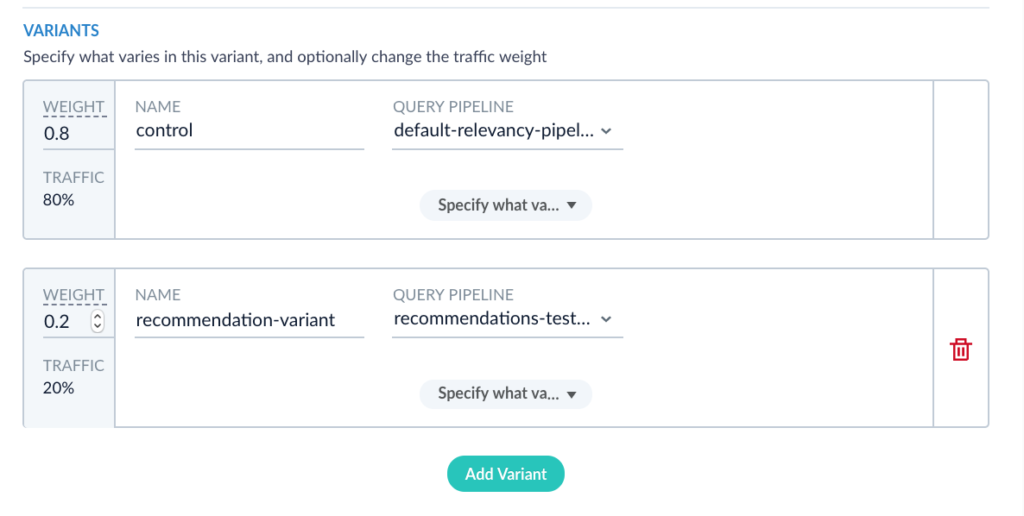
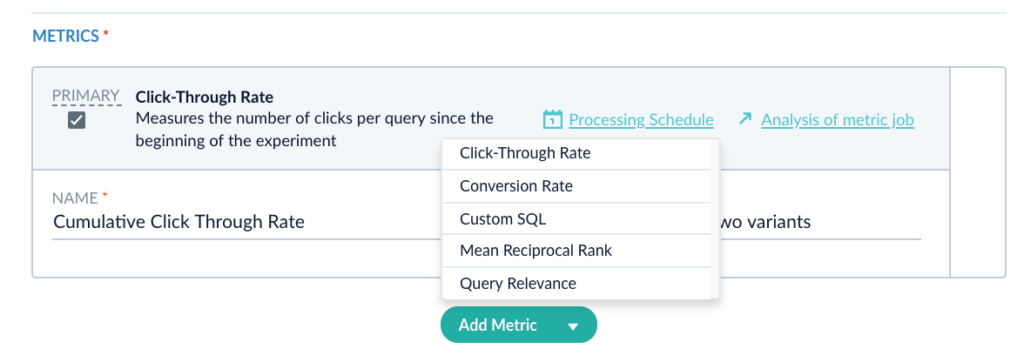
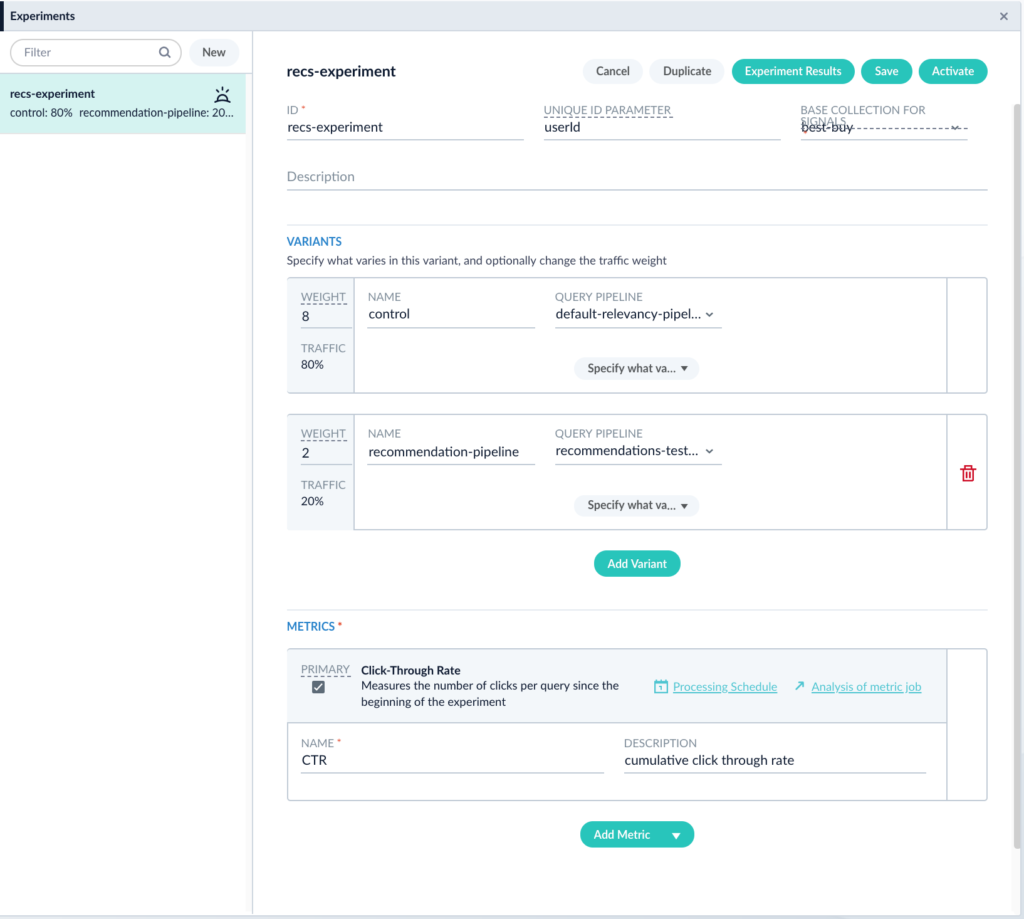
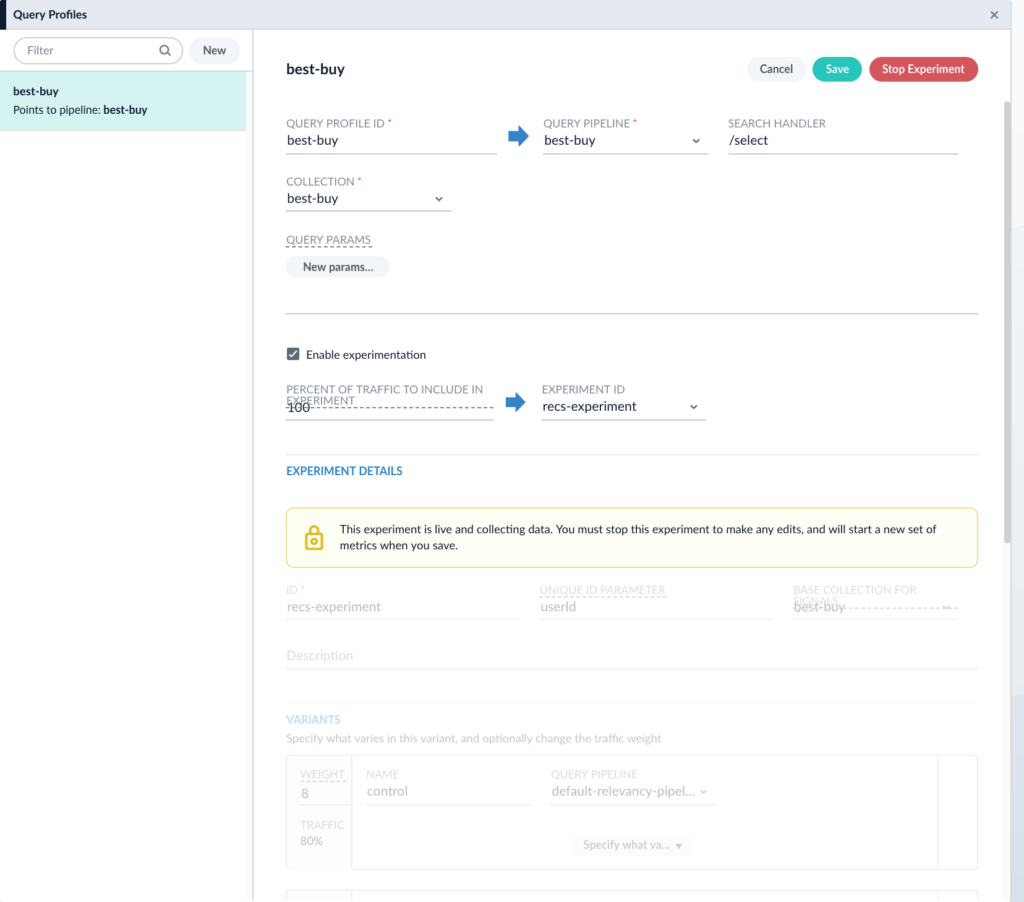
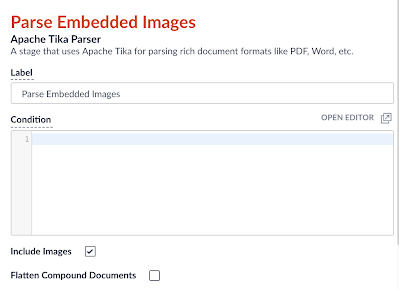
That Lucidworks Fusion is a great platform to integrate artificial intelligence with search can be seen by examining its architecture. Apache Spark serves as the engine by which machine learning jobs – either OOTB or custom – are scheduled and executed. The output of these jobs are the so-called ML “models” discussed above. To Fusion, a “model” can be simply considered as just a collection of bytes – a potentially large collection that in the tradition of the relational database nomenclature is called a BLOB ( which stands for Binary Large Object). Fusion contains a built-in repository we call the Blob Store that serves as the destination for these ML models. Once in the Blob Store, the model is accessable to our Index and Query Pipelines. As discussed above, machine learning is generally a two phase process in which supervised or unsupervised algorithms are used to learn something about a collection of content which is encapsulated in a model (phase 1). The model is then used to predict something about previously unseen content (phase 2). In Fusion, phase 1 (model training) is done using Fusion Apache Spark clusters and phase 2 is applied either to content sent to a Fusion search cluster for indexing into Solr via the Index Pipeline or to queries submitted to Fusion via the Query Pipeline through the intermediary of the Blob Store. In this way, the tagging or marking up content to enhance search-ability or inspecting the query to infer user intent or to re-rank results are achievable using the same basic plumbing.
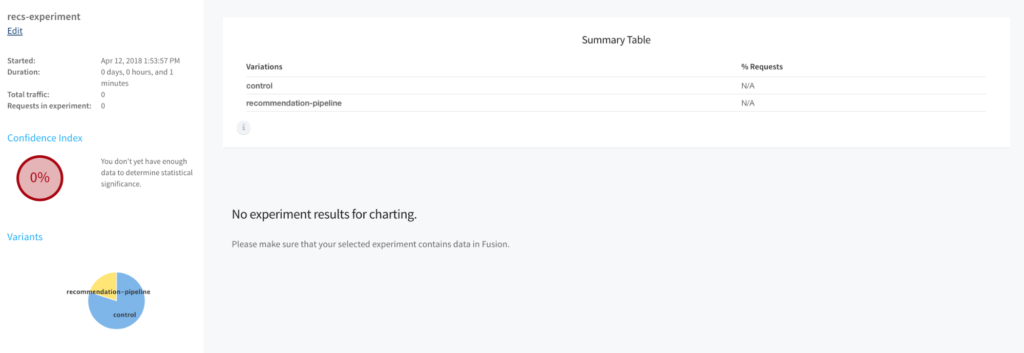
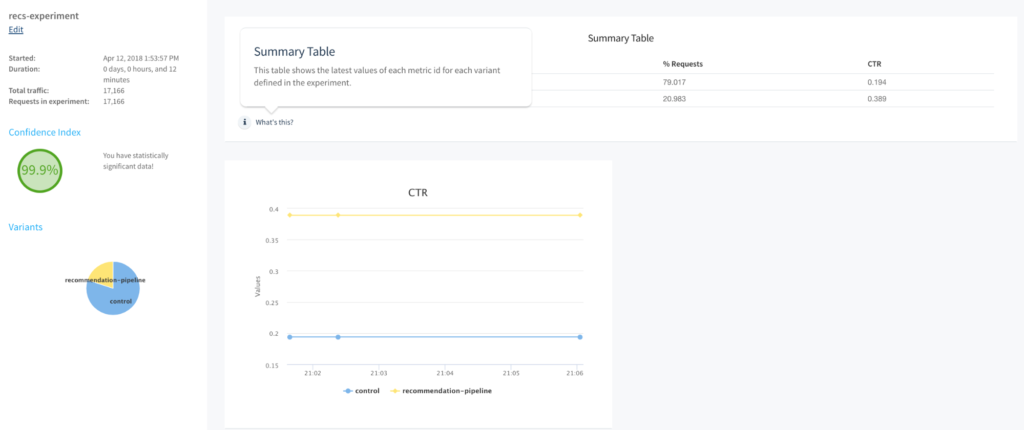
Signals, Machine Learning and Search Optimization
In addition to the plumbing, Fusion “bakes in” the ability to merge your data with information about how your users interact with it – enabling you to create search applications that become more useful the more they are used. We call this capability “signals”. In short, signals are metadata objects that describe user actions. It could be a mouse click on a document link, a click on a facet, an “add to cart”, or “bookmark URL”, or “download PDF” event. Other types of events could be “viewed page for 30 seconds” or “hovered over flyout description” – basically anything that your front-end search application can capture that your UX designers would consider to be an indicator of “interest” in a search result. The metadata describing the event is then sent to Fusion’s REST API to be indexed into the raw signals collection along with the id of the query that preceded the event. The signals collection automatically receives query events (as of Fusion 4.0 it functions as the query log collection as well).
Signals –> Aggregation –> Models –> Pipelines
Once you have acquired a sufficient amount of information on how users interact with your data, you can use this information to improve their search experience. The first step is to aggregate or roll-up the raw signal data so that statistical analyses can be done. Fusion comes with pre-built Spark aggregation jobs that you can use or you can roll your own if necessary. The resultant aggregations are stored back in Solr. At this point, we can use the aggregated data to train ML algorithms for a number of purposes – collaborative filtering, user intent classification, item to item or query to item recommendations, learning to rank and so on. The resulting models are put in the Blob Store where they can be used by Fusion Index or Query Pipeline stages to affect the desired transformations of incoming content or queries.
In this way, the Lucidworks architecture provides the perfect platform for the fusion of Search and Artificial Intelligence (pun very much intended!)
The post When Worlds Collide – Artificial Intelligence Meets Search appeared first on Lucidworks.