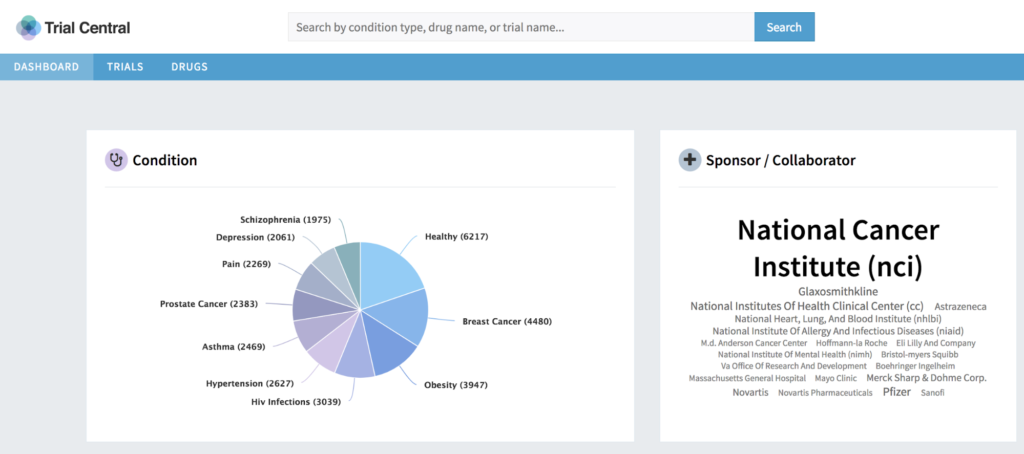
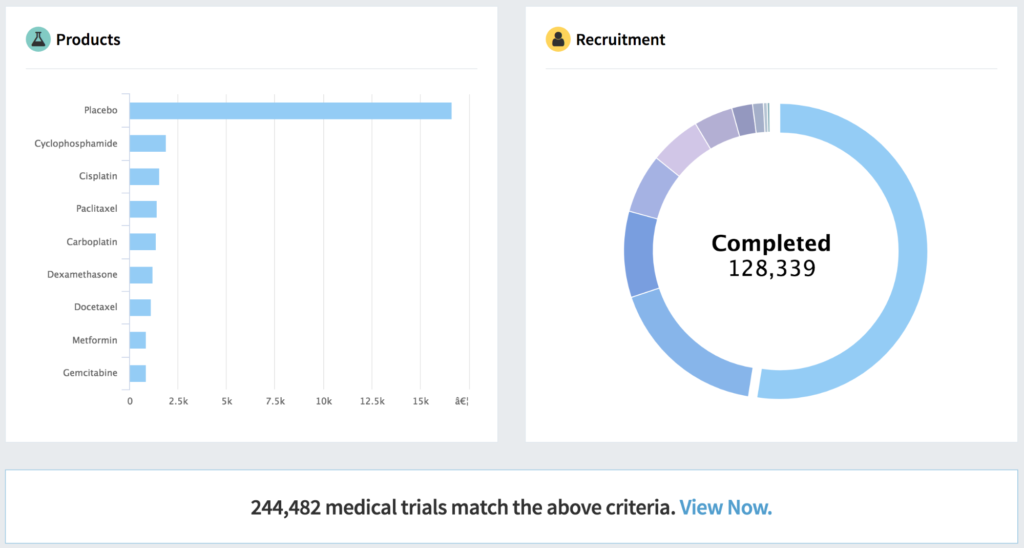
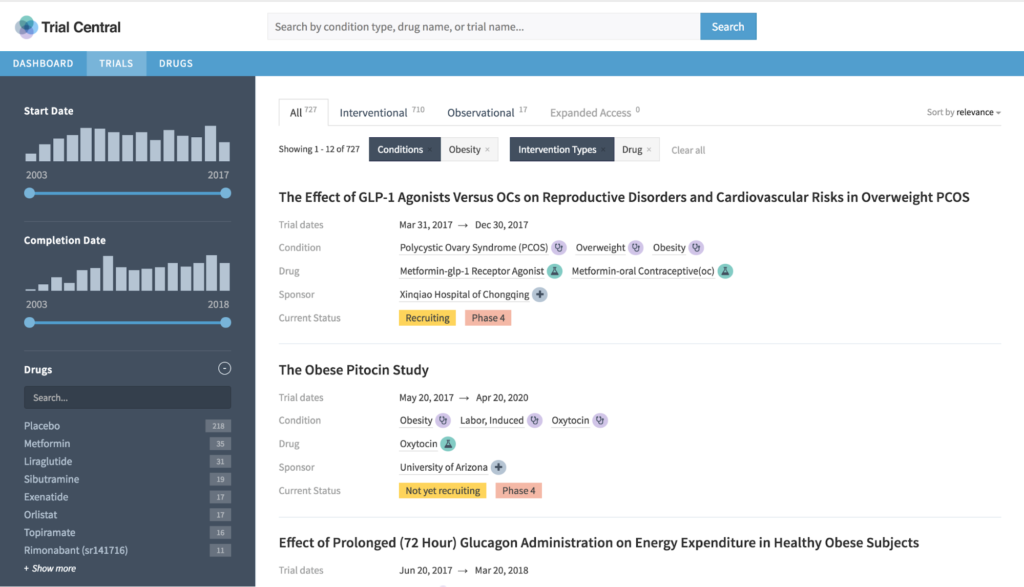
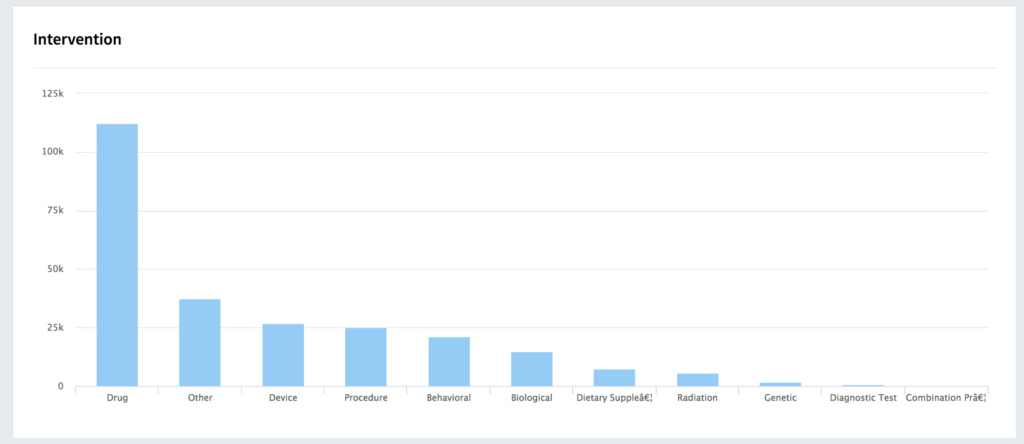
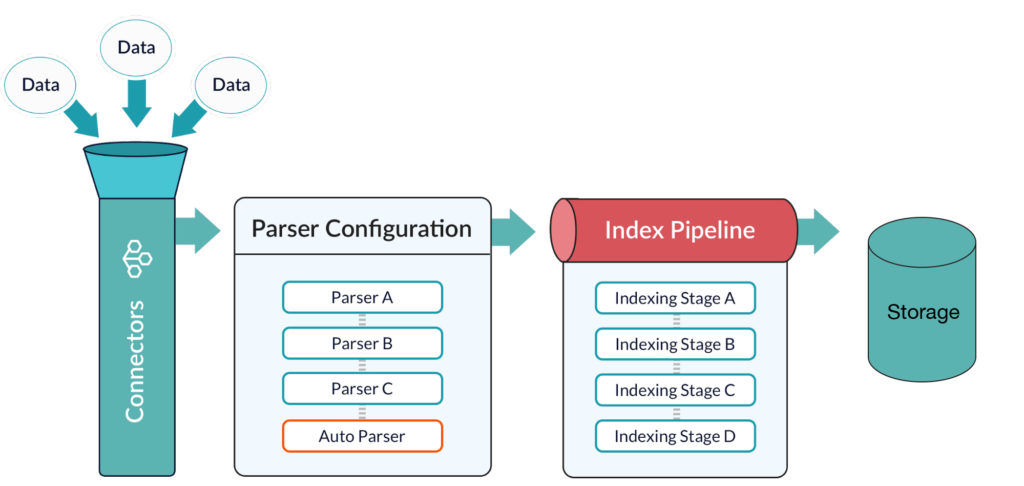
This post builds on my previous blog post, where I introduced the Fusion SQL service: https://lucidworks.com/2017/02/01/sql-in-fusion-3/. Since that post, we’ve been busy adding new optimizations and ensuring better integration with BI tools like Tableau, especially for larger datasets.
In the interest of time, I’ll assume you’re familiar with the concepts I covered in the previous blog post. In this post, I highlight several of the interesting features we’ve added in Fusion 4.1.
Querying Larger Datasets
The Solr community continues to push the limits in size and complexity of data sets that can be handled by Solr. In this year’s upcoming Activate Conference, a number of talks cover scaling Solr into the hundreds of millions to billions of documents. What’s more is that Solr can compute facets and basic aggregations (min, max, sum, count, avg, and percentiles) over these large data sets. The Fusion SQL service leverages Solr’s impressive scalability to offer SQL-based analytics over datasets containing tens to hundreds of millions of rows, often in near real-time without prior aggregation. To reach this scale with traditional BI platforms, you’re typically forced to pre-compute aggregations that can only satisfy a small set of predetermined queries.
Self-service analytics continues to rank high on the priority list of many CIOs, especially as organizations strive to be more “data-driven.” However, I can’t imagine CIOs letting business users point a tool like Tableau at even a modest scale dataset in Solr terms. However, Fusion SQL makes true self-service analytics a reality without having to resort to traditional data warehouse techniques.
To illustrate, let’s use the movielens 20M ratings dataset from https://grouplens.org/datasets/movielens/20m/. I chose this since it aligns with the dataset I used in the first blog post about Fusion SQL. To be clear, 20M is pretty small for Solr but as we’ll see shortly, already stresses traditional SQL databases like MySQL. To index this dataset, use Fusion’s Parallel Bulk Loader (https://doc.lucidworks.com/fusion-server/4.1/reference-guides/jobs/parallel-bulk-loader.html) using the Fusion Spark bootcamp lab: https://github.com/lucidworks/fusion-spark-bootcamp/tree/master/labs/ml-20m
(Note: you only need to run the lab to index the 20M ratings if you want to try out the queries in this blog yourself.)
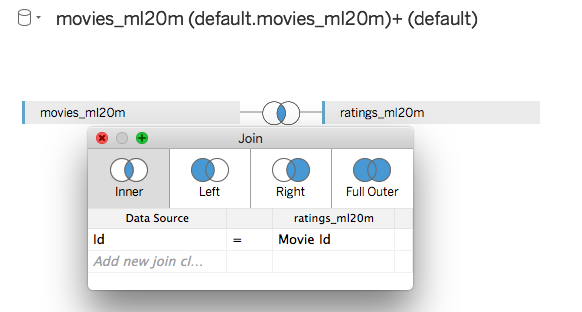
You can set up a join between the movies_ml20m table using (id) and ratings_ml20m table (movie_id) in Tableau as shown in the screenshot below.![Tableau screenshot]()
When the user loads 1000 rows, here’s what Tableau sends to the Fusion SQL service:
SELECT 1 AS `number_of_records`,
`movies_ml20m`.`genre` AS `genre`,
`ratings_ml20m`.`id` AS `id__ratings_ml20m_`,
`movies_ml20m`.`id` AS `id`,
`ratings_ml20m`.`movie_id` AS `movie_id`,
`ratings_ml20m`.`rating` AS `rating`,
`ratings_ml20m`.`timestamp_tdt` AS `timestamp_tdt`,
`movies_ml20m`.`title` AS `title`,
`ratings_ml20m`.`user_id` AS `user_id`
FROM `default`.`movies_ml20m` `movies_ml20m`
JOIN `default`.`ratings_ml20m` `ratings_ml20m` ON (`movies_ml20m`.`id` = `ratings_ml20m`.`movie_id`)
LIMIT 1000
Behind the scenes, Fusion SQL translates that into an optimized query into Solr. Of course, doing joins natively in Solr is no small feat given that Solr is at first a search engine that depends on de-normalized data to perform at its best. Behinds the scenes, Fusion SQL performs what’s known in the database world as a hash join between the ratings_ml20m and movies_ml20m collections using Solr’s streaming expression interface. On my laptop, this query takes about 2 seconds to return to Tableau with the bulk of that time being the read of 1000 rows from Solr to Tableau.
The same query against MySQL on my laptop takes ~4 seconds, so not a big difference, so far, so good. A quick table view of data is nice, but what we really want are aggregated metrics. This is where the Fusion SQL service really shines.
In my previous blog, I showed an example of an aggregate then join query:
SELECT m.title as title, agg.aggCount as aggCount FROM movies m INNER JOIN (SELECT movie_id, COUNT(*) as aggCount FROM ratings WHERE rating >= 4 GROUP BY movie_id ORDER BY aggCount desc LIMIT 10) as agg ON agg.movie_id = m.id ORDER BY aggCount DESC
Sadly, when I execute this against MySQL with an index built on the movie_id field in the ratings table, the query basically hangs (I gave up after waiting after a minute). For 20M rows, Fusion SQL does it in 1.2 seconds! I also tried MySQL on an Ec2 instance (r3.xlarge) and the query ran in 17 secs, which is still untenable for self-service analytics.
0: jdbc:hive2://localhost:8768/default> SELECT m.title as title, agg.aggCount as aggCount FROM movies_ml20m m INNER JOIN (SELECT movie_id, COUNT(*) as aggCount FROM ratings_ml20m WHERE rating >= 4 GROUP BY movie_id ORDER BY aggCount desc LIMIT 10) as agg ON agg.movie_id = m.id ORDER BY aggCount DESC;
![]()
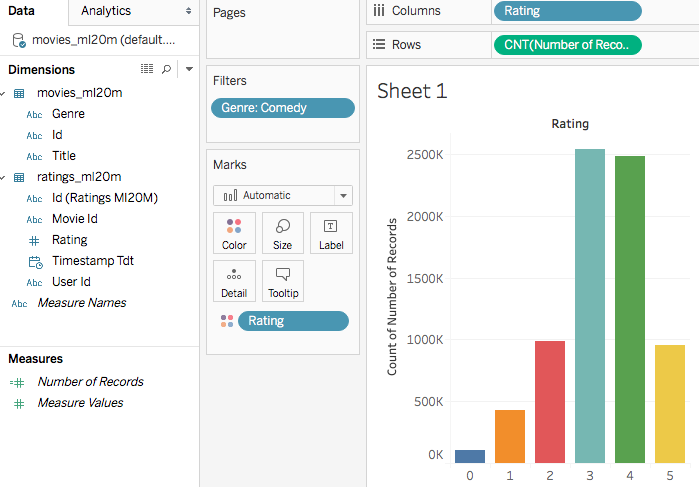
Ok, well maybe MySQL just doesn’t do the aggregate then join correctly there. Let’s try another more realistic query written by Tableau for the following chart:
![Tableau screeshot2]()
SELECT COUNT(1) AS `cnt_number_of_records_ok`,
`ratings_ml20m`.`rating` AS `rating`
FROM `default`.`movies_ml20m` `movies_ml20m`
JOIN `default`.`ratings_ml20m` `ratings_ml20m` ON (`movies_ml20m`.`id` = `ratings_ml20m`.`movie_id`)
WHERE (`movies_ml20m`.`genre` = ‘Comedy’)
GROUP BY `ratings_ml20m`.`rating`
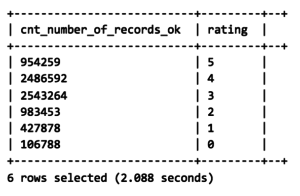
Fusion SQL executes this query in ~2 secs:
![]()
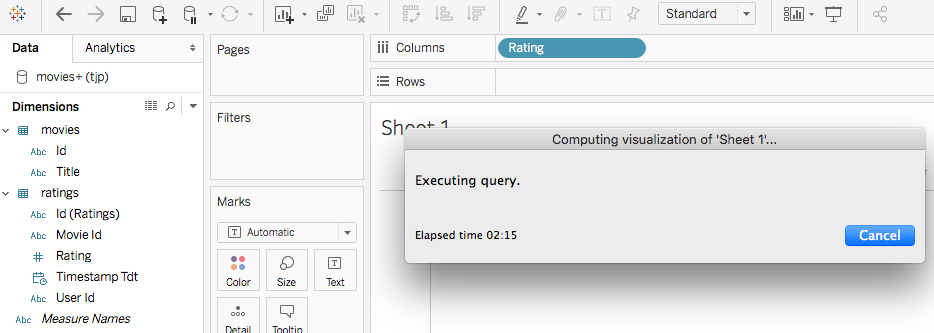
Let’s give that a try with MySQL. First it took >2 minutes to just get the unique values of the rating field, which Fusion SQL does almost instantly using facets:
![Fusion screenshot]()
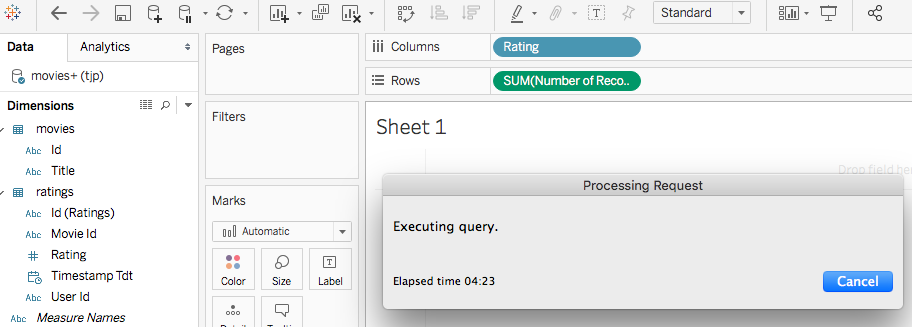
Again, this is against a modest (by Solr’s standards) 20M row table with an index built for the rating column. Then to draw the basic visualization, the query didn’t come back with several minutes (as seen below, we’re still waiting after 4 minutes, it finished around 5 minutes in).
![Fusion screenshot]()
The point here is not to pick on MySQL as I’m sure a good DBA could configure it to handle these basic aggregations sent by Tableau, or another database like Postgres or SQL Server may be faster. But as the data size scales up, you’ll eventually need to setup a data warehouse with some pre-computed aggregations to answer questions of interest about your dataset. The bigger point is that Fusion SQL allows the business analyst to point a data visualization tool like Tableau at large datasets to generate powerful dashboards and reports driven by ad hoc queries without using a data warehouse. In the age of big data, datasets are only getting bigger and more complex.
How Does Fusion Optimize SQL Queries?
A common SQL optimization pattern is to aggregate and then join so that the join works with a smaller set of aggregated rows instead of join then aggregate, which results in many more rows to join. It turns out that Solr’s facet engine is very well suited for aggregate then join style queries.
For aggregate then join, we can use Solr facets to compute metrics for the join key bucket and then perform the join. We also leverage Solr’s rollup streaming expression support to rollup over different dimensions. Of course, this only works for equi-joins where you use the join to attach metadata to the metrics from other tables. Over time, Fusion SQL will add more optimizations around other types of joins.
What About High-cardinality Fields?
If you’re familiar with Solr, than you probably already know that the distributed faceting engine can blaze through counting and basic metrics on buckets that have a low cardinality. But sometimes, a SQL query really needs dimensions that result in a large number of buckets to facet over (high cardinality). For example, imagine a group by over a field with a modest number of unique values ~100,000 but then grouped by a time dimension (week or day), and you can quickly get into a high cardinality situation (100K * 365 days * N years = lots of dimensions).
To deal with this situation, Fusion SQL tries to estimate the cardinality of fields in the group by clause and uses that to decide on the correct query strategy into Solr, either facet for low-cardinality or a map/reduce style streaming expression (rollup) for high cardinality. The key takeaway here is that you as the query writer don’t have to be as concerned about how to do this correctly with Solr streaming expressions. Fusion SQL handles the hard work of translating a SQL query into an optimized Solr query using the characteristics of the underlying data.
This raises the question of what constitutes high-cardinality. Let’s do a quick experiment on the ratings_ml20m table:
select count(1) as cnt, user_id from ratings_ml20m
group by user_id having count(1) > 1000 order by cnt desc limit 10
The query performs a count aggregation for each user in the ratings table ~138K. With faceting, this query executes in 1.8 secs on my laptop. When using the rollup streaming expression, the query takes over 40 seconds! So we’re still better off using faceting at this scale. Next, let’s add some more cardinality using the following aggregation over user_id and rating which has >800K unique values:
select count(1) as cnt, user_id, rating from ratings_ml20m
group by user_id, rating order by cnt desc limit 10
With faceting, this query takes 8 seconds and roughly a minute with rollup. The key takeaway here is the facet approach is much faster than rollup, even for nearly 1 million unique groups. However, depending on your data size and group by complexity you may reach a point where facet breaks down and you need to use rollup. You can configure the threshold where Fusion SQL uses rollup instead of facet using the fusion.sql.bucket_size_limit.threshold setting.
Full Text Queries
One of the nice features about having Solr as the backend for Fusion SQL is that we can perform full-text searches and sort by importance. In older versions of Fusion, we relied on pushing down a full subquery to Solr’s parallel SQL handler to perform a full-text query using the _query_ syntax. However, in Fusion 4.1, you can simply do:
select title from movies where plot_txt_en = ‘dogs’
or
select title from movies where plot_txt_en IN (‘dogs’, ‘cats’)
Fusion SQL consults the Solr schema API to know that plot_txt_en is an indexed text field and performs a full-text query instead of trying to do an exact match against the plot_txt_en field. Fusion SQL also exposes a UDF named _query_ where you can pass any valid Solr query through SQL to Solr, such as:
select place_name,zip_code from zipcodes where _query_(‘{!geofilt sfield=geo_location pt=44.9609,-93.2642 d=50}’)
Avoiding Table Scans
If we can’t pushdown an optimized query into Solr, what happens? Spark automatically pushes down WHERE filters and field projections to the spark-solr library. However, if a query matches 10M docs in Solr, then Spark will stream them from Solr in order to execute the query. As you can imagine, this may be slow depending on how many Solr nodes you have. We’ve seen table scan rates of 1-2M docs per second per Solr node, so reading 10M docs in a 3-node cluster could take 3-5 secs at best (plus a hefty I/O spike between Solr and Spark). Of course, we’ve optimized this as best we can in spark-solr, but the key takeaway here is to avoid queries that need large table scans from Solr.
One of the risks of pointing a self-service analytics tool at very large datasets is that users will craft a query that needs a large table scan, which can hog resources on your cluster. Fusion SQL has a configurable safe guard for this situation. By default if a query requires more than 2M rows, the query will fail. That may be too small of a threshold for larger clusters, so you can increase the threshold using the fusion.sql.max_scan_rows configuration property.
Wrap-up
In this post, I covered how Fusion SQL enables building rich visualizations using tools like Tableau on large datasets. By leveraging Solr’s facet engine and streaming expressions, you can perform SQL aggregations, ad hoc queries, and joins across millions of rows in Solr in near real-time. What’s more is that scaling out Fusion horizontally to handle bigger data sets has never been easier or more cost-effective, especially when compared to traditional BI approaches. If you’re looking to offer self-service analytics as a capability for your organization, then I encourage you to download Fusion 4.1 today and give the SQL service a try.
Next Steps:
The post Using Tableau, SQL, and Search for Fast Data Visualizations appeared first on Lucidworks.